Introducere
 Inteligența artificială se referă la utilizarea mașinilor pentru a ridica viața și stilul de viață al oamenilor, făcându-le viețile banale să fie interesante și simple sarcini redundante. Inteligența artificială nu ar trebui să fie niciodată o forță dominantă, ci una complementară care lucrează în tandem cu oamenii pentru a rezolva lucrurile neplauzibile și pentru a deschide calea pentru evoluția colectivă.
Inteligența artificială se referă la utilizarea mașinilor pentru a ridica viața și stilul de viață al oamenilor, făcându-le viețile banale să fie interesante și simple sarcini redundante. Inteligența artificială nu ar trebui să fie niciodată o forță dominantă, ci una complementară care lucrează în tandem cu oamenii pentru a rezolva lucrurile neplauzibile și pentru a deschide calea pentru evoluția colectivă.
Începând de acum, mergem pe calea cea bună, cu progrese semnificative înregistrându-se în industrii cu ajutorul AI. Dacă luați asistența medicală, de exemplu, sistemele AI însoțite de modele de învățare automată ajută experții să înțeleagă mai bine cancerul și să vină cu tratamente pentru acesta. Tulburările neurologice și preocupările precum PTSD sunt tratate cu ajutorul IA. Vaccinurile sunt dezvoltate în ritmuri rapide datorită studiilor și simulărilor clinice bazate pe inteligență artificială.
Nu doar asistența medicală, fiecare industrie sau segment pe care îl atinge AI este revoluționată. Vehiculele autonome, magazinele inteligente, dispozitivele portabile precum FitBit și chiar camerele noastre pentru smartphone-uri sunt capabile să surprindă imagini mai bune ale fețelor noastre cu ajutorul inteligenței artificiale.
Datorită inovațiilor care au loc în spațiul AI, companiile intră în spectru cu diverse cazuri de utilizare și soluții. Datorită acestui fapt, se anticipează că piața globală AI va atinge o valoare de piață de aproximativ 267 de miliarde de dolari până la sfârșitul anului 2027. În plus, aproximativ 37% dintre companiile de acolo implementează deja soluții AI în procesele și produsele lor.
Mai interesant, aproape 77% dintre produsele și serviciile pe care le folosim astăzi sunt alimentate de AI. Odată cu creșterea semnificativă a conceptului de tehnologie pe verticală, cum reușesc companiile să facă imposibil cu inteligența artificială?

 Cum dispozitivele la fel de simple ca un ceas prezic cu exactitate atacurile de cord la oameni? Cum este posibil ca mașinile și automobilele care au avut întotdeauna nevoie de un șofer să treacă dintr-o dată la șofer mai puțin pe drumuri?
Cum dispozitivele la fel de simple ca un ceas prezic cu exactitate atacurile de cord la oameni? Cum este posibil ca mașinile și automobilele care au avut întotdeauna nevoie de un șofer să treacă dintr-o dată la șofer mai puțin pe drumuri?
Cum ne fac chatboții să credem că vorbim cu un alt om de pe cealaltă parte?
Dacă observați răspunsul la fiecare întrebare, acesta se reduce la un singur element - DATE. Datele se află în centrul tuturor operațiunilor și proceselor specifice AI. Sunt datele care ajută mașinile să înțeleagă concepte, să proceseze intrările și să ofere rezultate precise.
Toate soluțiile AI majore care există sunt toate produsele unui proces crucial pe care îl numim colectare de date sau achiziție de date sau date de antrenament AI.
Acest ghid extins are rolul de a vă ajuta să înțelegeți ce este și de ce este important.
Ce este colectarea datelor AI?
Mașinile nu au o minte proprie. Absența acestui concept abstract îi face lipsiți de opinii, fapte și capacități, cum ar fi raționamentul, cunoașterea și multe altele. Sunt doar cutii imobile sau dispozitive care ocupă spațiu. Pentru a le transforma în medii puternice, aveți nevoie de algoritmi și, mai important, de date.
 Algoritmii care sunt dezvoltați au nevoie de ceva la care să lucreze și să proceseze și acel ceva sunt date relevante, contextuale și recente. Procesul de colectare a unor astfel de date pentru ca mașinile să-și servească scopurile propuse se numește colectare de date AI.
Algoritmii care sunt dezvoltați au nevoie de ceva la care să lucreze și să proceseze și acel ceva sunt date relevante, contextuale și recente. Procesul de colectare a unor astfel de date pentru ca mașinile să-și servească scopurile propuse se numește colectare de date AI.
Fiecare produs sau soluție cu inteligență artificială pe care o folosim astăzi și rezultatele pe care le oferă provin din ani de instruire, dezvoltare și optimizare. De la dispozitive care oferă rute de navigație până la acele sisteme complexe care prezic defecțiunile echipamentelor cu zile în avans, fiecare entitate a trecut prin ani de pregătire AI pentru a putea oferi rezultate cu acuratețe.
Colectarea datelor AI este pasul preliminar în procesul de dezvoltare a AI care determină încă de la început cât de eficient și eficient ar fi un sistem AI. Procesul de aprovizionare cu seturi de date relevante dintr-o multitudine de surse va ajuta modelele AI să proceseze mai bine detaliile și să producă rezultate semnificative.




Cum se colectează date pentru un Machine Learning?
 Aici lucrurile încep să devină puțin complicate. De la început, s-ar părea că ai în minte o soluție la o problemă din lumea reală, știi că AI ar fi modalitatea ideală de a rezolva asta și ți-ai dezvoltat modelele. Dar acum, vă aflați în faza crucială în care trebuie să vă începeți procesele de formare AI. Aveți nevoie de date abundente de antrenament AI cu dvs. pentru a face modelele dvs. să învețe concepte și să ofere rezultate. De asemenea, aveți nevoie de date de validare pentru a vă testa rezultatele și pentru a vă optimiza algoritmii.
Aici lucrurile încep să devină puțin complicate. De la început, s-ar părea că ai în minte o soluție la o problemă din lumea reală, știi că AI ar fi modalitatea ideală de a rezolva asta și ți-ai dezvoltat modelele. Dar acum, vă aflați în faza crucială în care trebuie să vă începeți procesele de formare AI. Aveți nevoie de date abundente de antrenament AI cu dvs. pentru a face modelele dvs. să învețe concepte și să ofere rezultate. De asemenea, aveți nevoie de date de validare pentru a vă testa rezultatele și pentru a vă optimiza algoritmii.
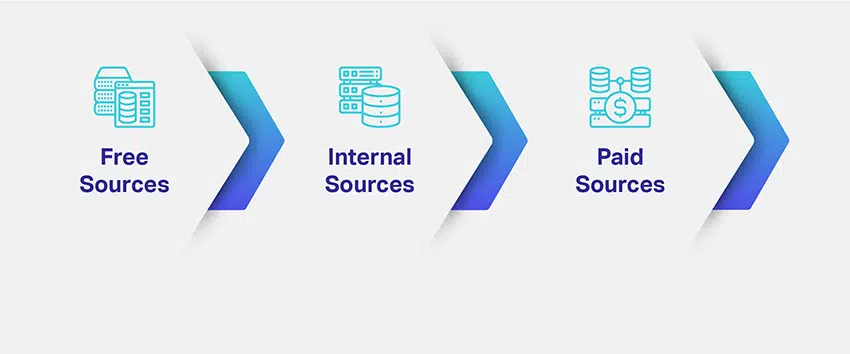
Deci, cum vă sursați datele? De ce date aveți nevoie și cât de mult din ele? Care sunt sursele multiple pentru a prelua date relevante?
Companiile evaluează nișa și scopul modelelor lor ML și elaborează modalități potențiale de a sursa seturi de date relevante. Definirea tipului de date necesar rezolvă o mare parte a preocupărilor dvs. privind aprovizionarea datelor. Pentru a vă face o idee mai bună, există diferite canale, căi, surse sau medii pentru colectarea datelor:
Cum vă afectează datele proaste ambițiile AI?
Am enumerat cele mai comune trei resurse de date pentru că veți avea o idee despre cum să abordați colectarea și aprovizionarea datelor. Cu toate acestea, în acest moment, devine esențial să înțelegeți, de asemenea, că decizia dvs. ar putea decide invariabil soarta soluției dvs. AI.
Similar cu modul în care datele de antrenament AI de înaltă calitate vă pot ajuta modelul să ofere rezultate precise și în timp util, datele de antrenament proaste pot, de asemenea, să distrugă modelele dvs. de AI, să modifice rezultatele, să introducă părtiniri și să ofere alte consecințe nedorite.
Dar de ce se întâmplă asta? Nu ar trebui date să antreneze și să optimizeze modelul dvs. de inteligență artificială? Sincer, nu. Să înțelegem asta mai departe.
Date proaste - Ce sunt?
 Date proaste sunt orice date care sunt irelevante, incorecte, incomplete sau părtinitoare. Datorită strategiilor de colectare a datelor prost definite, majoritatea oamenilor de știință ai datelor și experți în adnotare sunt forțați să lucreze pe date proaste.
Date proaste sunt orice date care sunt irelevante, incorecte, incomplete sau părtinitoare. Datorită strategiilor de colectare a datelor prost definite, majoritatea oamenilor de știință ai datelor și experți în adnotare sunt forțați să lucreze pe date proaste.
Diferența dintre datele nestructurate și cele proaste este că informațiile despre datele nestructurate sunt peste tot. Dar, în esență, ar putea fi utile indiferent. Petrecând timp suplimentar, oamenii de știință ar putea extrage informații relevante din seturi de date nestructurate. Cu toate acestea, nu este cazul cu datele proaste. Aceste seturi de date nu conțin informații sau informații care sunt valoroase sau relevante pentru proiectul dvs. AI sau pentru scopurile sale de instruire.
Așadar, atunci când îți aprovizionezi seturile de date din resurse gratuite sau ai puncte de contact de date interne bine stabilite, este foarte probabil să descărcați sau să generați date proaste. Când oamenii de știință lucrează la date proaste, nu doar pierzi ore umane, ci și impulsi lansarea produsului tău.
Dacă încă nu știți ce pot afecta datele proaste ambițiilor dvs., iată o listă rapidă:
- Petreceți nenumărate ore căutând date proaste și pierdeți ore, efort și bani pe resurse.
- Datele proaste vă pot provoca probleme legale, dacă nu sunt observate și pot reduce eficiența AI
modele. - Când vă instruiți produsul despre date proaste în direct, aceasta afectează experiența utilizatorului
- Datele proaste ar putea face ca rezultatele și concluziile să fie părtinitoare, ceea ce ar putea aduce și mai mult reacții negative.
Deci, dacă vă întrebați dacă există o soluție la asta, de fapt există.
AI Training Furnizori de date în ajutor
 Una dintre soluțiile de bază este să alegeți un furnizor de date (surse plătite). Furnizorii de date de instruire AI se asigură că ceea ce primiți este exact și relevant și că aveți seturi de date livrate într-o formă structurată. Nu trebuie să fii implicat în necazurile deplasării de la un portal la altul în căutarea seturi de date.
Una dintre soluțiile de bază este să alegeți un furnizor de date (surse plătite). Furnizorii de date de instruire AI se asigură că ceea ce primiți este exact și relevant și că aveți seturi de date livrate într-o formă structurată. Nu trebuie să fii implicat în necazurile deplasării de la un portal la altul în căutarea seturi de date.
Tot ce trebuie să faceți este să preluați datele și să vă antrenați modelele AI pentru perfecțiune. Acestea fiind spuse, suntem siguri că următoarea ta întrebare se referă la cheltuielile implicate în colaborarea cu furnizorii de date. Înțelegem că unii dintre voi lucrează deja la un buget mental și tocmai acolo ne îndreptăm și noi.
Factori de luat în considerare atunci când creați un buget eficient pentru proiectul dvs. de colectare a datelor
Instruirea AI este o abordare sistematică și de aceea bugetarea devine o parte integrantă a acesteia. Factori precum RoI, acuratețea rezultatelor, metodologiile de formare și multe altele ar trebui luați în considerare înainte de a investi o sumă masivă de bani în dezvoltarea AI. O mulțime de manageri de proiect sau proprietari de afaceri bâjbâie în această etapă. Ei iau decizii pripite care aduc schimbări ireversibile în procesul lor de dezvoltare a produselor, forțându-i în cele din urmă să cheltuiască mai mult.
Cu toate acestea, această secțiune vă va oferi informațiile potrivite. Când stai să lucrezi la bugetul pentru instruirea AI, trei lucruri sau factori sunt inevitabili.

Să ne uităm la fiecare în detaliu.
Volumul de date de care aveți nevoie
Am spus tot timpul că eficiența și acuratețea modelului tău AI depind de cât de mult este antrenat. Aceasta înseamnă că, cu cât este mai mare volumul de seturi de date, cu atât mai multă învățare. Dar acest lucru este foarte vag. Pentru a pune un număr la această noțiune, Dimensional Research a publicat un raport care a relevat că întreprinderile au nevoie de minimum 100,000 de seturi de date eșantion pentru a-și antrena modelele AI.
Prin 100,000 de seturi de date, ne referim la 100,000 de seturi de date relevante și de calitate. Aceste seturi de date ar trebui să aibă toate atributele esențiale, adnotările și perspectivele necesare pentru algoritmii și modelele de învățare automată pentru a procesa informații și a executa sarcinile propuse.
Cu aceasta este o regulă generală, să înțelegem în continuare că volumul de date de care aveți nevoie depinde și de un alt factor complex, care este cazul de utilizare al afacerii dvs. Ceea ce intenționați să faceți cu produsul sau soluția dvs. decide, de asemenea, de câte date aveți nevoie. De exemplu, o companie care construiește un motor de recomandare ar avea cerințe de volum de date diferite față de o companie care construiește un chatbot.
Strategia de prețuri pentru date
Când ați terminat de finalizat de câte date aveți de fapt nevoie, trebuie să lucrați în continuare la o strategie de preț pentru date. Acest lucru, în termeni simpli, înseamnă modul în care ați plăti pentru seturile de date pe care le achiziționați sau le generați.
În general, acestea sunt strategiile convenționale de prețuri urmate pe piață:
| Tipul de date | Strategia de stabilire a prețurilor |
|---|---|
| Prețul pentru un singur fișier imagine | |
| Prețul pe secundă, minut, oră sau cadru individual | |
| Prețul pe secundă, un minut sau o oră | |
| Preț pe cuvânt sau propoziție |
Dar asteapta. Aceasta este din nou o regulă de bază. Costul real al achiziției de seturi de date depinde și de factori precum:
- Segmentul unic de piață, datele demografice sau geografice din care trebuie să provină seturile de date
- Complexitatea cazului dvs. de utilizare
- De câte date aveți nevoie?
- Timpul tău pentru piață
- Orice cerințe personalizate și multe altele
Dacă observați, veți ști că costul pentru achiziționarea de cantități mari de imagini pentru proiectul dvs. AI ar putea fi mai mic, dar dacă aveți prea multe specificații, prețurile s-ar putea crește.
Strategiile dvs. de aprovizionare
Acest lucru este complicat. După cum ați văzut, există diferite moduri de a genera sau de a sursa date pentru modelele dvs. AI. Bunul simț ar dicta că resursele gratuite sunt cele mai bune, deoarece puteți descărca gratuit volumele necesare de seturi de date, fără complicații.
În acest moment, s-ar părea că sursele plătite sunt prea scumpe. Dar aici se adaugă un strat de complicație. Atunci când achiziționați seturi de date din resurse gratuite, cheltuiți o cantitate suplimentară de timp și efort pentru a curăța seturile de date, a le compila în formatul specific companiei și apoi a le adnotă individual. Suportați costuri operaționale în acest proces.
Cu surse plătite, plata este o singură dată și aveți, de asemenea, la îndemână seturi de date pregătite pentru mașină la momentul dorit. Eficiența costurilor este foarte subiectivă aici. Dacă simțiți că vă puteți permite să petreceți timp adnotând seturi de date gratuite, puteți bugeta în consecință. Și dacă credeți că concurența dvs. este acerbă și cu timp limitat de lansare pe piață, puteți crea un efect de unda pe piață, ar trebui să preferați sursele plătite.
Bugetarea înseamnă defalcarea specificului și definirea clară a fiecărui fragment. Acești trei factori ar trebui să vă servească drept foaie de parcurs pentru procesul de bugetare a instruirii AI în viitor.
Economisiți la cheltuieli cu achiziția internă de date?
 În timpul bugetului, am explorat modul în care resursele gratuite vă obligă să cheltuiți mai mult pe termen lung. În acel moment, te-ai fi întrebat automat despre rentabilitatea procesului intern de achiziție a datelor.
În timpul bugetului, am explorat modul în care resursele gratuite vă obligă să cheltuiți mai mult pe termen lung. În acel moment, te-ai fi întrebat automat despre rentabilitatea procesului intern de achiziție a datelor.
Știm că încă ezitați cu privire la sursele plătite și de aceea această secțiune vă va clarifica scepticismul cu privire la aceasta și va face lumină asupra costurilor ascunse implicate de generarea internă a datelor.
Achiziția internă de date este costisitoare?
Da, este!
Acum, iată un răspuns elaborat. Cheltuiala este orice cheltuiește. În timp ce discutam despre resursele gratuite, am dezvăluit că cheltuiți bani, timp și efort în proces. Acest lucru este valabil și pentru achiziția internă de date.
 Din cauza faptului că aveți puncte de contact sau canale de date personalizate, aceasta nu înseamnă că ați avea seturi de date pregătite pentru mașină la sfarsit. Datele pe care le generați vor fi în continuare în mare parte brute și nestructurate. S-ar putea să aveți toate datele de care aveți nevoie într-un singur loc, dar ceea ce conțin datele va fi peste tot.
Din cauza faptului că aveți puncte de contact sau canale de date personalizate, aceasta nu înseamnă că ați avea seturi de date pregătite pentru mașină la sfarsit. Datele pe care le generați vor fi în continuare în mare parte brute și nestructurate. S-ar putea să aveți toate datele de care aveți nevoie într-un singur loc, dar ceea ce conțin datele va fi peste tot.
În cele din urmă, veți ajunge să cheltuiți pentru a vă plăti angajații, oamenii de știință de date, adnotatorii, profesioniștii în asigurarea calității și multe altele. De asemenea, veți cheltui pe abonamente pentru instrumente de adnotare și
întreținerea CMS, CRM și alte cheltuieli de infrastructură.
În plus, seturile de date trebuie să aibă probleme de părtinire și acuratețe, de care aveți nevoie pentru a le sorta manual. Și dacă aveți o problemă de uzură în echipa dvs. de date de instruire AI, va trebui să cheltuiți pentru recrutarea de noi membri, orientarea acestora către procesele dvs., instruirea lor pentru a vă folosi instrumentele și multe altele.
Veți ajunge să cheltuiți mai mult decât ați câștiga în cele din urmă pe termen lung. Există și cheltuieli de adnotare. În orice moment dat, costul total suportat pentru a lucra cu datele interne este:
Costul suportat = Numărul de adnotatori * Costul pe adnotator + Costul platformei
Dacă calendarul tău de antrenament AI este programat pentru luni, imaginați-vă cheltuielile pe care le-ați suporta în mod constant. Deci, este aceasta soluția ideală pentru problemele de achiziție de date sau există vreo alternativă?
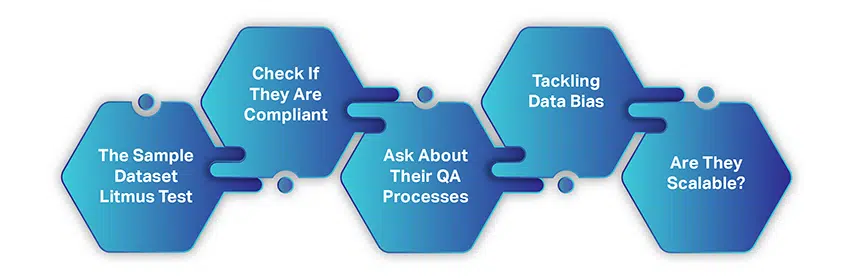
Cum să alegi compania potrivită de colectare a datelor AI
Alegerea unei companii de colectare a datelor AI nu este la fel de complicată sau consumatoare de timp precum colectarea datelor din resurse gratuite. Există doar câțiva factori simpli pe care trebuie să îi luați în considerare și apoi să vă dați mâna pentru o colaborare.
Când începeți să căutați un furnizor de date, presupunem că ați urmărit și luat în considerare orice am discutat până acum. Cu toate acestea, iată o scurtă recapitulare:
- Aveți în minte un caz de utilizare bine definit
- Segmentul dvs. de piață și cerințele de date sunt clar stabilite
- Bugetul dvs. este la punct
- Și aveți o idee despre volumul de date de care aveți nevoie
Cu aceste elemente bifate, haideți să înțelegem cum puteți căuta un furnizor ideal de servicii de date de formare.