
Recunoașterea automată a vorbirii (ASR) a parcurs un drum lung. Deși a fost inventat cu mult timp în urmă, nu a fost folosit aproape niciodată de nimeni. Cu toate acestea, timpul și tehnologia s-au schimbat acum semnificativ. Transcrierea audio a evoluat substanțial.
Tehnologii precum AI (Inteligenta Artificiala) au alimentat procesul de traducere audio in text pentru rezultate rapide si precise. Drept urmare, aplicațiile sale din lumea reală au crescut, de asemenea, unele aplicații populare precum Tik Tok, Spotify și Zoom încorporând procesul în aplicațiile lor mobile.
Deci, haideți să explorăm ASR și să descoperim de ce este una dintre cele mai populare tehnologii în 2022.
Ce este vorbirea în text?
Speech to text este o tehnologie îmbunătățită de AI care traduce vorbirea umană dintr-o formă analogică într-o formă digitală. În plus, forma digitală a datelor colectate este transcrisă într-un format text.
Discursul în text este adesea confundat cu recunoașterea vocii, care este complet diferită de această metodă. În recunoașterea vocii, accentul se pune pe identificarea tiparelor de voce ale oamenilor, în timp ce, în această metodă, sistemul încearcă să identifice cuvintele rostite.
Nume comune de vorbire în text
Această tehnologie avansată de recunoaștere a vorbirii este, de asemenea, populară și menționată prin numele:
- Recunoaștere automată a vorbirii (ASR)
- Recunoaștere a vorbirii
- Recunoașterea vorbirii pe computer
- Transcriere audio
- Citirea ecranului
Înțelegerea funcționării recunoașterii automate a vorbirii
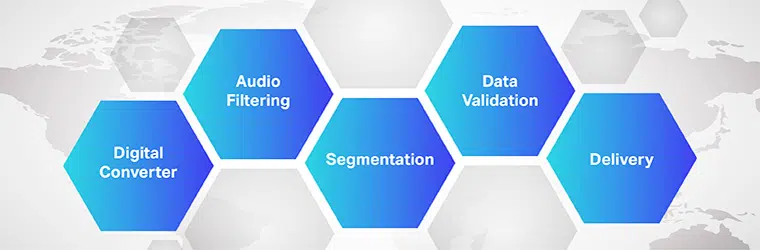
Funcționarea software-ului de traducere audio în text este complexă și implică implementarea mai multor pași. După cum știm, speech-to-text este un software exclusiv conceput pentru a converti fișierele audio într-un format de text editabil; o face prin valorificarea recunoașterii vocii.
Proces
- Inițial, folosind un convertor analog-digital, un program de calculator aplică algoritmi lingvistici datelor furnizate pentru a distinge vibrațiile de semnalele auditive.
- Apoi, sunetele relevante sunt filtrate prin măsurarea undelor sonore.
- În plus, sunetele sunt distribuite/segmentate în sutimi sau miimi de secunde și potrivite cu foneme (O unitate măsurabilă a sunetului pentru a diferenția un cuvânt de altul).
- Fonemele sunt parcurse în continuare printr-un model matematic pentru a compara datele existente cu cuvinte, propoziții și fraze binecunoscute.
- Ieșirea este într-un fișier text sau audio pe computer.
[Citește și: O prezentare cuprinzătoare a recunoașterii automate a vorbirii]

Care sunt utilizările vorbirii în text?
Există mai multe utilizări ale software-ului de recunoaștere automată a vorbirii, cum ar fi
- Căutare de conținut: Cei mai mulți dintre noi au trecut de la tastarea de litere pe telefoanele noastre la apăsarea unui buton pentru ca software-ul să ne recunoască vocea și să ofere rezultatele dorite.
- Customer Service: Chatboții și asistenții AI care pot ghida clienții prin cei câțiva pași inițiali ai procesului au devenit obișnuiți.
- Subtitrări în timp real: Odată cu accesul global sporit la conținut, subtitrările în timp real au devenit o piață proeminentă și semnificativă, împingând ASR pentru utilizarea sa.
- Documentatie electronica: Mai multe departamente de administrare au început să folosească ASR pentru a îndeplini scopurile de documentare, oferind o mai bună viteză și eficiență.
Care sunt provocările cheie ale recunoașterii vorbirii?
Adnotare audio nu a atins încă apogeul dezvoltării sale. Există încă multe provocări pe care inginerii încearcă să le contracareze pentru a face sistemul eficient, cum ar fi
- Obținerea controlului asupra accentelor și dialectelor.
- Înțelegerea contextului propozițiilor rostite.
- Separarea zgomotelor de fond pentru a amplifica calitatea intrării.
- Comutarea codului în diferite limbi pentru o procesare eficientă.
- Analizarea indiciilor vizuale utilizate în discurs în cazul fișierelor video.
Trancrieri audio și dezvoltare AI Speech-to-Text
Cea mai mare provocare cu software-ul de recunoaștere automată a vorbirii este crearea rezultatelor sale cu acuratețe 100%. Deoarece datele brute sunt dinamice și nu poate fi aplicat un singur algoritm, datele sunt adnotate pentru a antrena AI să le înțeleagă în contextul potrivit.
Pentru a efectua acest proces, trebuie implementate sarcini specifice, cum ar fi:
 Recunoașterea entității denumite (NER): NER este procesul de identificare și segmentare a diferitelor entități numite în categorii specifice.
Recunoașterea entității denumite (NER): NER este procesul de identificare și segmentare a diferitelor entități numite în categorii specifice.- Analiza sentimentelor și a subiectului: Software-ul care utilizează mai mulți algoritmi efectuează analiza sentimentului datelor furnizate pentru a oferi rezultate fără erori.
 Recunoașterea entității denumite (NER):
Recunoașterea entității denumite (NER): - Analiza intenției și a conversației: Detectarea intenției urmărește să antreneze AI să recunoască intenția vorbitorului. Este folosit în principal pentru crearea de chatbot-uri bazate pe inteligență artificială.
Concluzie
Tehnologia Speech-to-text se află într-un stadiu excelent în acest moment. Cu mai multe dispozitive digitale care încorporează asistenți de căutare și control vocal în aplicațiile lor, cererea de transcriere audio este setat să crească. Dacă doriți să adăugați această caracteristică impresionantă aplicației dvs., contactați experții Shaip în colectarea datelor despre vorbire pentru a afla detaliile complete.


