
Introducere
Acest ghid va fi extrem de util acelor cumpărători și factori de decizie care încep să-și îndrepte gândurile către elementele de bază ale aprovizionării datelor și implementării datelor atât pentru rețelele neuronale, cât și pentru alte tipuri de operațiuni AI și ML.

Acest articol este complet dedicat pentru a face lumină asupra procesului, de ce este inevitabil, crucial
factorii pe care companiile ar trebui să ia în considerare atunci când abordează instrumentele de adnotare a datelor și nu numai. Deci, dacă dețineți o afacere, pregătiți-vă pentru a vă informa, deoarece acest ghid vă va ghida prin tot ce trebuie să știți despre adnotarea datelor.
Să începem.
Pentru cei dintre voi care răsfoiți articolul, iată câteva informații rapide pe care le veți găsi în ghid:
- Înțelegeți ce este adnotarea datelor
- Cunoașteți diferitele tipuri de procese de adnotare a datelor
- Cunoașteți avantajele implementării procesului de adnotare a datelor
- Obțineți clar dacă ar trebui să optați pentru etichetarea internă a datelor sau să le externalizați
- Informații despre alegerea corectă a adnotărilor de date
Ce este învățarea automată?
 Am vorbit despre cum adnotarea datelor sau etichetarea datelor acceptă învățarea automată și că constă în etichetarea sau identificarea componentelor. Dar în ceea ce privește învățarea profundă și învățarea automată în sine: premisa de bază a învățării automate este că sistemele și programele computerizate își pot îmbunătăți rezultatele în moduri care seamănă cu procesele cognitive umane, fără ajutor sau intervenție umană directă, pentru a ne oferi perspective. Cu alte cuvinte, ei devin mașini de auto-învățare care, la fel ca un om, devin mai buni la locul de muncă cu mai multă practică. Această „practică” este obținută din analiza și interpretarea mai multor (și mai bune) date de antrenament.
Am vorbit despre cum adnotarea datelor sau etichetarea datelor acceptă învățarea automată și că constă în etichetarea sau identificarea componentelor. Dar în ceea ce privește învățarea profundă și învățarea automată în sine: premisa de bază a învățării automate este că sistemele și programele computerizate își pot îmbunătăți rezultatele în moduri care seamănă cu procesele cognitive umane, fără ajutor sau intervenție umană directă, pentru a ne oferi perspective. Cu alte cuvinte, ei devin mașini de auto-învățare care, la fel ca un om, devin mai buni la locul de muncă cu mai multă practică. Această „practică” este obținută din analiza și interpretarea mai multor (și mai bune) date de antrenament.
Ce este adnotarea datelor?
Adnotarea datelor este procesul de atribuire, etichetare sau etichetare a datelor pentru a ajuta algoritmii de învățare automată să înțeleagă și să clasifice informațiile pe care le procesează. Acest proces este esențial pentru antrenarea modelelor AI, permițându-le să înțeleagă cu precizie diferite tipuri de date, cum ar fi imagini, fișiere audio, înregistrări video sau text.
Imaginați-vă o mașină cu conducere autonomă care se bazează pe date din viziunea computerizată, procesarea limbajului natural (NLP) și senzori pentru a lua decizii precise de conducere. Pentru a ajuta modelul AI al mașinii să facă diferența între obstacole precum alte vehicule, pietoni, animale sau blocaje rutiere, datele pe care le primește trebuie să fie etichetate sau adnotate.
În învățarea supravegheată, adnotarea datelor este deosebit de crucială, deoarece cu cât sunt mai multe date etichetate furnizate modelului, cu atât mai repede învață să funcționeze autonom. Datele adnotate permit ca modelele AI să fie implementate în diverse aplicații, cum ar fi chatbot, recunoașterea vorbirii și automatizarea, rezultând performanțe optime și rezultate fiabile.
Ce este un instrument de etichetare/adnotare a datelor?
 În termeni simpli, este o platformă sau un portal care permite specialiștilor și experților să adnoteze, să eticheteze sau să eticheteze seturi de date de toate tipurile. Este o punte sau un mijloc între datele brute și rezultatele pe care modulele dvs. de învățare automată le-ar produce în cele din urmă.
În termeni simpli, este o platformă sau un portal care permite specialiștilor și experților să adnoteze, să eticheteze sau să eticheteze seturi de date de toate tipurile. Este o punte sau un mijloc între datele brute și rezultatele pe care modulele dvs. de învățare automată le-ar produce în cele din urmă.
Un instrument de etichetare a datelor este o soluție locală sau bazată pe cloud, care adnotă date de instruire de înaltă calitate pentru modelele de învățare automată. În timp ce multe companii se bazează pe un furnizor extern pentru a face adnotări complexe, unele organizații au în continuare propriile instrumente, care sunt fie personalizate, fie se bazează pe instrumente freeware sau opensource disponibile pe piață. Astfel de instrumente sunt de obicei concepute pentru a gestiona anumite tipuri de date, de exemplu, imagine, video, text, audio etc. Instrumentele oferă caracteristici sau opțiuni precum casete de delimitare sau poligoane pentru adnotatorii de date pentru a eticheta imaginile. Ei pot doar să selecteze opțiunea și să își îndeplinească sarcinile specifice.
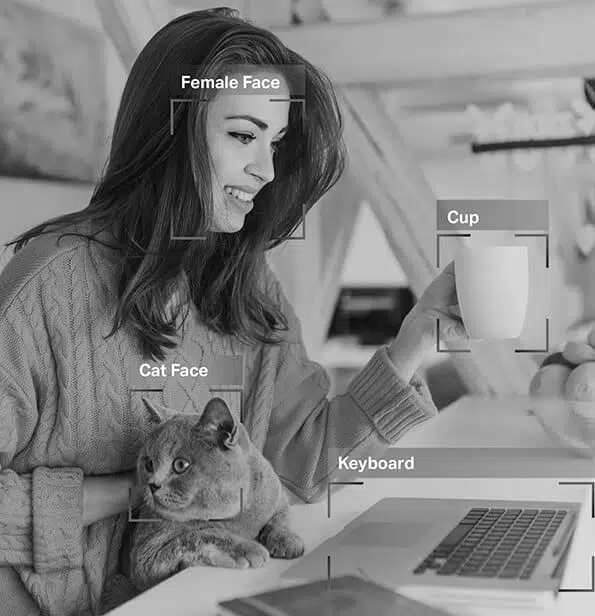
Adnotarea imaginii

Din seturile de date pe care au fost instruiți, aceștia vă pot diferenția instantaneu și precis ochii de nas și sprânceana de gene. De aceea, filtrele pe care le aplicați se potrivesc perfect, indiferent de forma feței dvs., cât de aproape sunteți de camera dvs. și multe altele.
Deci, după cum știți acum, adnotarea imaginii este vital în modulele care implică recunoașterea facială, viziunea computerizată, viziunea robotică și multe altele. Când experții în inteligență artificială antrenează astfel de modele, ei adaugă subtitrări, identificatori și cuvinte cheie ca atribute imaginilor lor. Algoritmii identifică și înțeleg apoi acești parametri și învață în mod autonom.
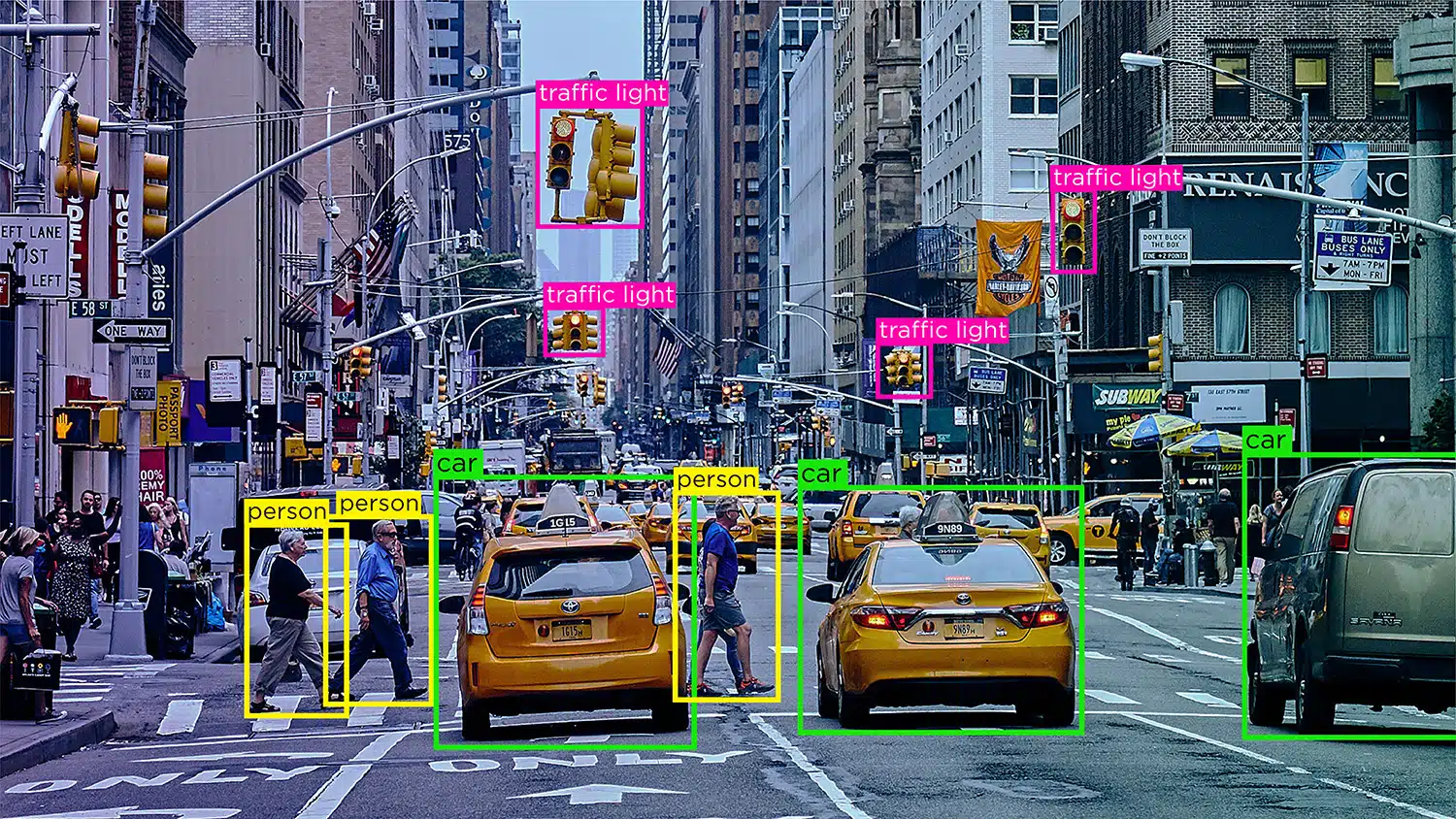
Clasificarea imaginilor - Clasificarea imaginilor implică atribuirea unor categorii sau etichete predefinite imaginilor în funcție de conținutul acestora. Acest tip de adnotare este folosit pentru a instrui modelele AI să recunoască și să clasifice imaginile automat.
Recunoaștere/Detecție obiect – Recunoașterea obiectelor, sau detectarea obiectelor, este procesul de identificare și etichetare a unor obiecte specifice dintr-o imagine. Acest tip de adnotare este folosit pentru a antrena modele AI pentru a localiza și recunoaște obiecte în imagini sau videoclipuri din lumea reală.
Segmentarea – Segmentarea imaginii presupune împărțirea unei imagini în mai multe segmente sau regiuni, fiecare corespunzând unui anumit obiect sau zone de interes. Acest tip de adnotare este folosit pentru a instrui modelele AI să analizeze imagini la nivel de pixeli, permițând recunoașterea mai precisă a obiectelor și înțelegerea scenei.
Adnotare audio
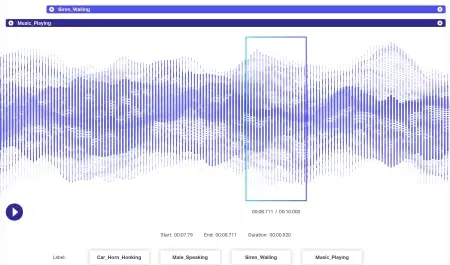
Datele audio au și mai multă dinamică atașată decât datele de imagine. Mai mulți factori sunt asociați cu un fișier audio, inclusiv, dar cu siguranță nu se limitează la - limba, demografia vorbitorului, dialectele, starea de spirit, intenția, emoția, comportamentul. Pentru ca algoritmii să fie eficienți în procesare, toți acești parametri ar trebui identificați și etichetați prin tehnici precum marcarea temporală, etichetarea audio și multe altele. Pe lângă indicii pur și simplu verbale, cazurile non-verbale precum tăcerea, respirațiile, chiar și zgomotul de fundal ar putea fi adnotate pentru ca sistemele să înțeleagă în mod cuprinzător.
Adnotare video

În timp ce o imagine este nemișcată, un videoclip este o compilație de imagini care creează un efect al obiectelor în mișcare. Acum, fiecare imagine din această compilație se numește cadru. În ceea ce privește adnotarea video, procesul implică adăugarea de puncte cheie, poligoane sau casete de delimitare pentru a adnota diferite obiecte din câmp în fiecare cadru.
Când aceste cadre sunt cusute împreună, mișcarea, comportamentul, modelele și multe altele ar putea fi învățate de modelele AI în acțiune. Este doar prin adnotare video că concepte precum localizarea, estomparea mișcării și urmărirea obiectelor ar putea fi implementate în sisteme.
Adnotare text

Astăzi, majoritatea companiilor se bazează pe date bazate pe text pentru o perspectivă și informații unice. Acum, textul ar putea fi orice, de la feedback-ul clienților despre o aplicație până la o mențiune pe rețelele sociale. Și, spre deosebire de imagini și videoclipuri care transmit în mare parte intenții directe, textul vine cu multă semantică.
Ca oameni, suntem adaptați să înțelegem contextul unei fraze, sensul fiecărui cuvânt, propoziție sau frază, să le raportăm la o anumită situație sau conversație și apoi să realizăm sensul holistic din spatele unei afirmații. Mașinile, pe de altă parte, nu pot face acest lucru la niveluri precise. Concepte precum sarcasmul, umorul și alte elemente abstracte le sunt necunoscute și de aceea etichetarea datelor text devine mai dificilă. De aceea, adnotarea textului are câteva etape mai rafinate, cum ar fi următoarele:
Adnotare semantică – obiectele, produsele și serviciile devin mai relevante prin etichetarea expresiilor cheie și parametrii de identificare corespunzători. Chatbot-urile sunt, de asemenea, făcute să imite conversațiile umane în acest fel.
Adnotare de intenție – intenția unui utilizator și limba folosită de acesta sunt etichetate pentru ca mașinile să poată înțelege. Cu aceasta, modelele pot diferenția o solicitare de o comandă, sau recomandare de o rezervare și așa mai departe.
Adnotarea sentimentelor – Adnotarea sentimentelor implică etichetarea datelor textuale cu sentimentul pe care îl transmite, cum ar fi pozitiv, negativ sau neutru. Acest tip de adnotare este folosit în mod obișnuit în analiza sentimentelor, unde modelele AI sunt antrenate să înțeleagă și să evalueze emoțiile exprimate în text.

Adnotare entitate – unde propozițiile nestructurate sunt etichetate pentru a le face mai semnificative și pentru a le aduce într-un format care poate fi înțeles de mașini. Pentru ca acest lucru să se întâmple, sunt implicate două aspecte - denumită recunoaștere a entității și legarea entității. Recunoașterea entităților numite este atunci când sunt etichetate și identificate nume de locuri, persoane, evenimente, organizații și altele, iar legarea de entități este atunci când aceste etichete sunt legate de propoziții, fraze, fapte sau opinii care le urmează. Colectiv, aceste două procese stabilesc relația dintre textele asociate și enunțul care îl înconjoară.
Categorizarea textului – Propozițiile sau paragrafele pot fi etichetate și clasificate în funcție de subiecte generale, tendințe, subiecte, opinii, categorii (sport, divertisment și similare) și alți parametri.
Pași cheie în procesul de etichetare și adnotare a datelor
Procesul de adnotare a datelor implică o serie de pași bine definiți pentru a asigura etichetarea datelor de înaltă calitate și precisă pentru aplicațiile de învățare automată. Acești pași acoperă fiecare aspect al procesului, de la colectarea datelor până la exportul datelor adnotate pentru utilizare ulterioară.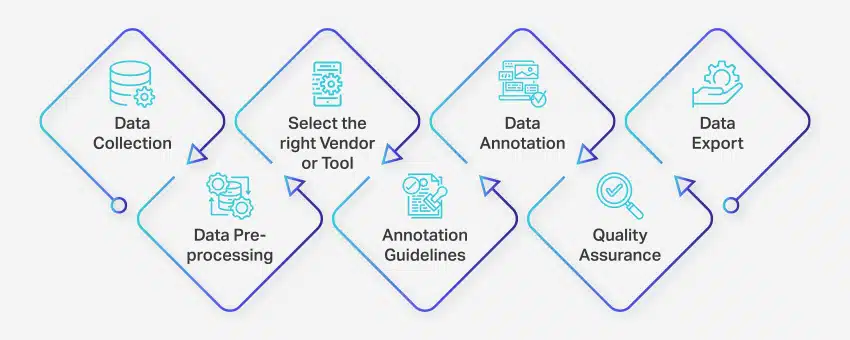
Iată cum are loc adnotarea datelor:
- Colectare de date: Primul pas în procesul de adnotare a datelor este adunarea tuturor datelor relevante, cum ar fi imagini, videoclipuri, înregistrări audio sau date text, într-o locație centralizată.
- Preprocesarea datelor: Standardizați și îmbunătățiți datele colectate prin deschizarea imaginilor, formatarea textului sau transcrierea conținutului video. Preprocesarea asigură că datele sunt gata pentru adnotare.
- Selectați furnizorul sau instrumentul potrivit: Alegeți un instrument adecvat de adnotare a datelor sau un furnizor în funcție de cerințele proiectului dvs. Opțiunile includ platforme precum Nanonets pentru adnotarea datelor, V7 pentru adnotarea imaginilor, Appen pentru adnotarea video și Nanonets pentru adnotarea documentelor.
- Ghid pentru adnotare: Stabiliți linii directoare clare pentru adnotatori sau instrumente de adnotare pentru a asigura coerența și acuratețea pe tot parcursul procesului.
- Adnotare: Etichetați și etichetați datele folosind adnotatori umani sau software de adnotare a datelor, urmând instrucțiunile stabilite.
- Asigurarea calității (QA): Examinați datele adnotate pentru a asigura acuratețea și coerența. Folosiți mai multe adnotări oarbe, dacă este necesar, pentru a verifica calitatea rezultatelor.
- Export de date: După finalizarea adnotării datelor, exportați datele în formatul necesar. Platforme precum Nanonets permit exportul de date fără întreruperi în diverse aplicații software de afaceri.
Întregul proces de adnotare a datelor poate varia de la câteva zile la câteva săptămâni, în funcție de dimensiunea proiectului, complexitatea și resursele disponibile.
Caracteristici pentru instrumentele de adnotare și etichetare a datelor
Instrumentele de adnotare a datelor sunt factori decisivi care ar putea face sau distruge proiectul dvs. AI. Când vine vorba de rezultate și rezultate precise, calitatea seturilor de date în sine nu contează. De fapt, instrumentele de adnotare a datelor pe care le utilizați pentru a vă instrui modulele AI vă influențează enorm rezultatele.
De aceea, este esențial să selectați și să utilizați cel mai funcțional și adecvat instrument de etichetare a datelor care să răspundă nevoilor afacerii sau proiectului dumneavoastră. Dar ce este, în primul rând, un instrument de adnotare a datelor? Ce scop serveste? Există tipuri? Ei bine, hai să aflăm.
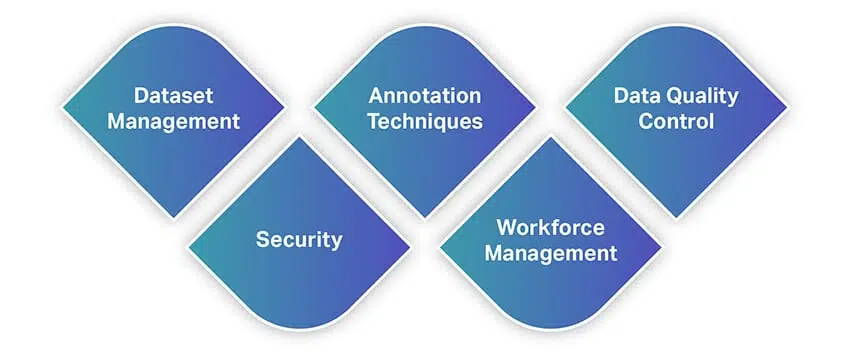
Similar cu alte instrumente, instrumentele de adnotare a datelor oferă o gamă largă de caracteristici și capabilități. Pentru a vă face o idee rapidă despre funcții, iată o listă cu unele dintre cele mai fundamentale caracteristici pe care ar trebui să le căutați atunci când selectați un instrument de adnotare a datelor.
Managementul seturilor de date
Instrumentul de adnotare a datelor pe care intenționați să îl utilizați trebuie să accepte seturile de date pe care le aveți în mână și să vă permită să le importați în software pentru etichetare. Așadar, gestionarea setului de date este oferta principală de instrumente pentru funcții. Soluțiile contemporane oferă caracteristici care vă permit să importați volume mari de date fără probleme, permițându-vă simultan să vă organizați seturile de date prin acțiuni precum sortarea, filtrarea, clonarea, îmbinare și multe altele.
Odată ce se termină introducerea setului de date, urmează să le exportați ca fișiere utilizabile. Instrumentul pe care îl utilizați ar trebui să vă permită să vă salvați seturile de date în formatul specificat de dvs., astfel încât să le puteți introduce în modelele ML.
Tehnici de adnotare
Pentru asta este construit sau proiectat un instrument de adnotare a datelor. Un instrument solid ar trebui să vă ofere o gamă largă de tehnici de adnotare pentru seturi de date de toate tipurile. Asta dacă nu dezvoltați o soluție personalizată pentru nevoile dvs. Instrumentul dvs. ar trebui să vă permită să adnotați videoclipuri sau imagini din viziune computerizată, audio sau text din NLP-uri și transcrieri și multe altele. Rafinând acest lucru în continuare, ar trebui să existe opțiuni pentru a utiliza casete de delimitare, segmentare semantică, cuboizi, interpolare, analiză a sentimentelor, părți de vorbire, soluție de coreferență și multe altele.
Pentru cei neinițiați, există și instrumente de adnotare a datelor bazate pe inteligență artificială. Acestea vin cu module AI care învață în mod autonom din modelele de lucru ale unui adnotator și adnotă automat imagini sau text. Astfel de
modulele pot fi folosite pentru a oferi asistență incredibilă adnotatorilor, pentru a optimiza adnotările și chiar pentru a implementa verificări de calitate.
Controlul calității datelor
Vorbind despre verificări de calitate, există câteva instrumente de adnotare a datelor cu module de verificare a calității încorporate. Acestea permit adnotatorilor să colaboreze mai bine cu membrii echipei lor și ajută la optimizarea fluxurilor de lucru. Cu această funcție, adnotatorii pot marca și urmări comentariile sau feedback-ul în timp real, pot urmări identitățile din spatele persoanelor care fac modificări la fișiere, pot restaura versiunile anterioare, pot opta pentru consensul de etichetare și multe altele.
Securitate
Deoarece lucrați cu date, securitatea ar trebui să fie de cea mai mare prioritate. Este posibil să lucrați la date confidențiale, cum ar fi cele care implică detalii personale sau proprietate intelectuală. Deci, instrumentul dvs. trebuie să ofere securitate etanșă în ceea ce privește locul în care sunt stocate datele și modul în care sunt partajate. Trebuie să ofere instrumente care să limiteze accesul membrilor echipei, să prevină descărcările neautorizate și multe altele.
În afară de acestea, standardele și protocoalele de securitate trebuie îndeplinite și respectate.
Managementul fortei de munca
Un instrument de adnotare a datelor este, de asemenea, o platformă de management de proiect, unde sarcinile pot fi atribuite membrilor echipei, se poate lucra în colaborare, sunt posibile recenzii și multe altele. De aceea, instrumentul dvs. ar trebui să se încadreze în fluxul dvs. de lucru și proces pentru o productivitate optimizată.
În plus, instrumentul trebuie să aibă, de asemenea, o curbă minimă de învățare, deoarece procesul de adnotare a datelor în sine necesită mult timp. Nu servește la niciun scop petrecerea prea mult timp pur și simplu învățând instrumentul. Deci, ar trebui să fie intuitiv și fără probleme pentru oricine să înceapă rapid.
Care sunt beneficiile adnotării datelor?
Adnotarea datelor este crucială pentru optimizarea sistemelor de învățare automată și pentru a oferi experiențe îmbunătățite pentru utilizatori. Iată câteva beneficii cheie ale adnotării datelor:
- Eficiență îmbunătățită a antrenamentului: Etichetarea datelor ajută modelele de învățare automată să fie mai bine instruite, sporind eficiența generală și producând rezultate mai precise.
- Precizie sporită: Datele adnotate cu precizie asigură că algoritmii se pot adapta și învăța în mod eficient, rezultând niveluri mai mari de precizie în sarcinile viitoare.
- Intervenție umană redusă: Instrumentele avansate de adnotare a datelor reduc semnificativ nevoia de intervenție manuală, eficientizarea proceselor și reducerea costurilor asociate.
Astfel, adnotarea datelor contribuie la sisteme de învățare automată mai eficiente și mai precise, minimizând în același timp costurile și efortul manual necesar în mod tradițional pentru antrenarea modelelor AI.
Pentru a construi sau nu a construi un instrument de adnotare a datelor
O problemă critică și generală care poate apărea în timpul unui proiect de adnotare sau etichetare a datelor este alegerea de a construi sau de a cumpăra funcționalități pentru aceste procese. Acest lucru poate apărea de mai multe ori în diferite faze ale proiectului sau legat de diferite segmente ale programului. Atunci când alegeți dacă să construiți un sistem intern sau să vă bazați pe furnizori, există întotdeauna un compromis.

După cum probabil vă puteți da seama acum, adnotarea datelor este un proces complex. În același timp, este și un proces subiectiv. Adică, nu există un singur răspuns la întrebarea dacă ar trebui să cumpărați sau să construiți un instrument de adnotare a datelor. Trebuie luați în considerare o mulțime de factori și trebuie să vă puneți câteva întrebări pentru a vă înțelege cerințele și pentru a vă da seama dacă într-adevăr trebuie să cumpărați sau să construiți unul.
Pentru a face acest lucru simplu, iată câțiva dintre factorii pe care ar trebui să îi luați în considerare.
Scopul tău
Primul element pe care trebuie să-l definiți este scopul cu inteligența artificială și conceptele de învățare automată.
- De ce le implementați în afacerea dvs.?
- Rezolvă o problemă reală cu care se confruntă clienții tăi?
- Realizează vreun proces front-end sau backend?
- Veți folosi AI pentru a introduce noi funcții sau pentru a vă optimiza site-ul, aplicația sau modul existent?
- Ce face competitorul tău în segmentul tău?
- Aveți suficiente cazuri de utilizare care necesită intervenție AI?
Răspunsurile la acestea vă vor aduna gândurile – care pot fi în prezent peste tot – într-un singur loc și vă vor oferi mai multă claritate.
Colectarea datelor AI / Licențiere
Modelele AI necesită un singur element pentru funcționare – datele. Trebuie să identificați de unde puteți genera volume masive de date de la sol. Dacă afacerea dvs. generează volume mari de date care trebuie procesate pentru informații cruciale despre afaceri, operațiuni, cercetarea concurenților, analiza volatilității pieței, studiul comportamentului clienților și multe altele, aveți nevoie de un instrument de adnotare a datelor. Cu toate acestea, ar trebui să luați în considerare și volumul de date pe care îl generați. După cum am menționat mai devreme, un model AI este la fel de eficient ca și calitatea și cantitatea datelor pe care le furnizează. Deci, deciziile tale ar trebui să depindă invariabil de acest factor.
Dacă nu aveți datele potrivite pentru a vă antrena modelele ML, furnizorii vă pot fi foarte util, ajutându-vă cu acordarea licenței de date pentru setul potrivit de date necesare pentru instruirea modelelor ML. În unele cazuri, o parte din valoarea pe care o aduce vânzătorul va implica atât pricepere tehnică, cât și acces la resurse care vor promova succesul proiectului.
Buget
O altă condiție fundamentală care influențează probabil fiecare factor despre care discutăm în prezent. Soluția la întrebarea dacă ar trebui să construiți sau să cumpărați o adnotare de date devine ușoară atunci când înțelegeți dacă aveți suficient buget de cheltuit.
Complexități de conformitate
 Furnizorii pot fi extrem de folositori atunci când vine vorba de confidențialitatea datelor și de manipularea corectă a datelor sensibile. Unul dintre aceste tipuri de cazuri de utilizare implică un spital sau o afacere legată de asistența medicală care dorește să utilizeze puterea învățării automate fără a-și pune în pericol conformitatea cu HIPAA și alte reguli de confidențialitate a datelor. Chiar și în afara domeniului medical, legi precum GDPR european întăresc controlul asupra seturilor de date și necesită mai multă vigilență din partea părților interesate corporative.
Furnizorii pot fi extrem de folositori atunci când vine vorba de confidențialitatea datelor și de manipularea corectă a datelor sensibile. Unul dintre aceste tipuri de cazuri de utilizare implică un spital sau o afacere legată de asistența medicală care dorește să utilizeze puterea învățării automate fără a-și pune în pericol conformitatea cu HIPAA și alte reguli de confidențialitate a datelor. Chiar și în afara domeniului medical, legi precum GDPR european întăresc controlul asupra seturilor de date și necesită mai multă vigilență din partea părților interesate corporative.
Manpower
Adnotarea datelor necesită forță de muncă calificată pentru a lucra indiferent de dimensiunea, scara și domeniul afacerii dvs. Chiar dacă generați un minim de date în fiecare zi, aveți nevoie de experți în date care să lucreze la datele dvs. pentru etichetare. Deci, acum, trebuie să vă dați seama dacă aveți forța de muncă necesară. Dacă o faceți, sunt ei calificați cu instrumentele și tehnicile necesare sau au nevoie de perfecționare? Dacă au nevoie de perfecţionare, ai bugetul necesar pentru a-i instrui în primul rând?
În plus, cele mai bune programe de adnotare și etichetare a datelor preiau un număr de experți în materie sau domeniu și îi segmentează în funcție de criterii demografice, cum ar fi vârsta, sexul și domeniul de expertiză – sau adesea în ceea ce privește limbile localizate cu care vor lucra. Aici, din nou, noi, cei de la Shaip, vorbim despre atragerea oamenilor potriviți la locurile potrivite, conducând astfel procesele potrivite de om în buclă, care vă vor conduce eforturile programatice către succes.
Operațiuni de proiecte mici și mari și praguri de cost
În multe cazuri, asistența furnizorilor poate fi mai mult o opțiune pentru un proiect mai mic sau pentru faze mai mici de proiect. Atunci când costurile sunt controlabile, compania poate beneficia de externalizare pentru a eficientiza proiectele de adnotare sau etichetare a datelor.
Companiile pot, de asemenea, să se uite la praguri importante – în care mulți furnizori leagă costul de cantitatea de date consumată sau de alte repere de resurse. De exemplu, să presupunem că o companie s-a înscris cu un furnizor pentru a efectua introducerea plictisitoare de date necesară pentru configurarea seturilor de testare.
Poate exista un prag ascuns în acord în care, de exemplu, partenerul de afaceri trebuie să scoată un alt bloc de stocare a datelor AWS sau o altă componentă de serviciu de la Amazon Web Services sau de la un alt furnizor terță parte. Ei trec acest lucru către client sub formă de costuri mai mari, iar eticheta de preț nu este la îndemâna clientului.
În aceste cazuri, măsurarea serviciilor pe care le obțineți de la furnizori ajută la menținerea unui proiect la prețuri accesibile. Având un domeniu de aplicare adecvat, se va asigura că costurile proiectului nu depășesc ceea ce este rezonabil sau fezabil pentru firma în cauză.
Alternative open source și freeware
 Unele alternative la asistența completă a furnizorilor implică utilizarea de software open-source, sau chiar freeware, pentru a întreprinde proiecte de adnotare sau etichetare a datelor. Aici există un fel de cale de mijloc în care companiile nu creează totul de la zero, dar evită și să se bazeze prea mult pe furnizorii comerciali.
Unele alternative la asistența completă a furnizorilor implică utilizarea de software open-source, sau chiar freeware, pentru a întreprinde proiecte de adnotare sau etichetare a datelor. Aici există un fel de cale de mijloc în care companiile nu creează totul de la zero, dar evită și să se bazeze prea mult pe furnizorii comerciali.
Mentalitatea „do-it-yourself” a open source este ea însăși un fel de compromis – inginerii și oamenii interni pot profita de comunitatea open-source, unde bazele de utilizatori descentralizate oferă propriile tipuri de suport la nivel local. Nu va fi ca ceea ce obțineți de la un furnizor – nu veți primi asistență ușoară 24/7 sau răspunsuri la întrebări fără a face cercetări interne – dar prețul este mai mic.
Deci, marea întrebare - Când ar trebui să cumpărați un instrument de adnotare a datelor:
Ca și în cazul multor tipuri de proiecte de înaltă tehnologie, acest tip de analiză - când să construiți și când să cumpărați - necesită o gândire dedicată și o luare în considerare a modului în care aceste proiecte sunt preluate și gestionate. Provocările cu care se confruntă majoritatea companiilor legate de proiectele AI/ML atunci când iau în considerare opțiunea „construire” sunt că nu este vorba doar despre porțiunile de construcție și dezvoltare ale proiectului. Există adesea o curbă enormă de învățare pentru a ajunge chiar la punctul în care poate avea loc o adevărată dezvoltare AI/ML. Cu noile echipe și inițiative AI/ML, numărul de „necunoscute necunoscute” depășește cu mult numărul de „necunoscute cunoscute”.
| Construi | Proprietăți |
|---|---|
Pro-uri:
| Pro-uri:
|
Contra:
| Contra:
|
Pentru a simplifica lucrurile, luați în considerare următoarele aspecte:
- atunci când lucrați la volume masive de date
- atunci când lucrați pe diverse varietăți de date
- atunci când funcționalitățile asociate modelelor sau soluțiilor dvs. s-ar putea schimba sau evolua în viitor
- atunci când aveți un caz de utilizare vag sau generic
- atunci când aveți nevoie de o idee clară cu privire la cheltuielile implicate în implementarea unui instrument de adnotare a datelor
- și atunci când nu aveți forța de muncă potrivită sau experții calificați pentru a lucra la instrumente și sunteți în căutarea unei curbe minime de învățare
Dacă răspunsurile dvs. au fost opuse acestor scenarii, ar trebui să vă concentrați pe construirea instrumentului dvs.
Cum să alegeți instrumentul potrivit de adnotare a datelor pentru proiectul dvs
Dacă citiți asta, aceste idei sună interesante și sunt cu siguranță mai ușor de spus decât de făcut. Deci, cum se poate profita de multitudinea de instrumente de adnotare a datelor deja existente? Deci, următorul pas implicat este luarea în considerare a factorilor asociați cu alegerea instrumentului potrivit de adnotare a datelor.
Spre deosebire de câțiva ani în urmă, piața a evoluat cu tone de instrumente de adnotare a datelor în practică astăzi. Companiile au mai multe opțiuni în alegerea uneia în funcție de nevoile lor distincte. Dar fiecare instrument vine cu propriul său set de argumente pro și contra. Pentru a lua o decizie înțeleaptă, trebuie luată o cale obiectivă, în afară de cerințele subiective.
Să ne uităm la câțiva dintre factorii cruciali pe care ar trebui să îi luați în considerare în acest proces.
Definirea cazului dvs. de utilizare
Pentru a selecta instrumentul potrivit de adnotare a datelor, trebuie să vă definiți cazul de utilizare. Ar trebui să vă dați seama dacă cerințele dvs. implică text, imagine, video, audio sau un amestec de toate tipurile de date. Există instrumente independente pe care le puteți cumpăra și există instrumente holistice care vă permit să executați diverse acțiuni pe seturi de date.
Instrumentele de astăzi sunt intuitive și vă oferă opțiuni în ceea ce privește facilitățile de stocare (rețea, locală sau cloud), tehnici de adnotare (audio, imagine, 3D și multe altele) și o mulțime de alte aspecte. Puteți alege un instrument în funcție de cerințele dumneavoastră specifice.
Stabilirea standardelor de control al calității
 Acesta este un factor crucial de luat în considerare, deoarece scopul și eficiența modelelor dvs. AI depind de standardele de calitate pe care le stabiliți. La fel ca un audit, trebuie să efectuați verificări de calitate ale datelor pe care le furnizați și ale rezultatelor obținute pentru a înțelege dacă modelele dvs. sunt instruite în mod corect și în scopurile potrivite. Cu toate acestea, întrebarea este cum intenționați să stabiliți standarde de calitate?
Acesta este un factor crucial de luat în considerare, deoarece scopul și eficiența modelelor dvs. AI depind de standardele de calitate pe care le stabiliți. La fel ca un audit, trebuie să efectuați verificări de calitate ale datelor pe care le furnizați și ale rezultatelor obținute pentru a înțelege dacă modelele dvs. sunt instruite în mod corect și în scopurile potrivite. Cu toate acestea, întrebarea este cum intenționați să stabiliți standarde de calitate?
Ca și în cazul multor tipuri diferite de locuri de muncă, mulți oameni pot face o adnotare și etichetare a datelor, dar o fac cu diferite grade de succes. Când solicitați un serviciu, nu verificați automat nivelul de control al calității. De aceea rezultatele variază.
Deci, doriți să implementați un model de consens, în care adnotatorii oferă feedback cu privire la calitate și măsuri corective sunt luate instantaneu? Sau, preferați revizuirea eșantionului, standardele de aur sau intersecția în detrimentul modelelor de uniune?
Cel mai bun plan de cumpărare va asigura controlul calității de la bun început prin stabilirea standardelor înainte ca orice contract final să fie convenit. Când stabiliți acest lucru, nu trebuie să treceți cu vederea și marjele de eroare. Intervenția manuală nu poate fi evitată complet, deoarece sistemele sunt obligate să producă erori la rate de până la 3%. Acest lucru necesită muncă în avans, dar merită.
Cine va adnota datele dvs.?
Următorul factor major se bazează pe cine vă adnotă datele. Intenționați să aveți o echipă internă sau preferați să o externalizați? Dacă externalizați, există legalități și măsuri de conformitate pe care trebuie să le luați în considerare din cauza preocupărilor legate de confidențialitate și confidențialitate asociate datelor. Și dacă aveți o echipă internă, cât de eficienți sunt ei în învățarea unui nou instrument? Care este timpul dvs. de lansare pe piață cu produsul sau serviciul dvs.? Aveți valorile de calitate și echipele potrivite pentru a aproba rezultatele?
Vânzătorul vs. Dezbaterea partenerilor
 Adnotarea datelor este un proces colaborativ. Implica dependențe și complexități precum interoperabilitatea. Aceasta înseamnă că anumite echipe lucrează întotdeauna în tandem unele cu altele și una dintre echipe ar putea fi furnizorul dvs. De aceea, furnizorul sau partenerul pe care îl selectați este la fel de important ca instrumentul pe care îl utilizați pentru etichetarea datelor.
Adnotarea datelor este un proces colaborativ. Implica dependențe și complexități precum interoperabilitatea. Aceasta înseamnă că anumite echipe lucrează întotdeauna în tandem unele cu altele și una dintre echipe ar putea fi furnizorul dvs. De aceea, furnizorul sau partenerul pe care îl selectați este la fel de important ca instrumentul pe care îl utilizați pentru etichetarea datelor.
Cu acest factor, aspecte precum capacitatea de a vă păstra datele și intențiile confidențiale, intenția de a accepta și de a lucra la feedback, a fi proactiv în ceea ce privește solicitările de date, flexibilitatea în operațiuni și multe altele ar trebui luate în considerare înainte de a da mâna cu un furnizor sau un partener. . Am inclus flexibilitate, deoarece cerințele de adnotare a datelor nu sunt întotdeauna liniare sau statice. Acestea s-ar putea schimba în viitor, pe măsură ce vă extindeți afacerea. Dacă în prezent aveți de-a face doar cu date bazate pe text, este posibil să doriți să adnotați date audio sau video pe măsură ce scalați, iar asistența dvs. ar trebui să fie gata să le extindă orizonturile împreună cu dvs.
Implicarea furnizorului
Una dintre modalitățile de a evalua implicarea furnizorului este sprijinul pe care îl veți primi.
Orice plan de cumpărare trebuie să aibă în vedere această componentă. Cum va arăta suportul pe teren? Cine vor fi părțile interesate și oamenii indicați de ambele părți ale ecuației?
Există, de asemenea, sarcini concrete care trebuie să precizeze care este (sau va fi) implicarea vânzătorului. În special pentru un proiect de adnotare sau etichetare a datelor, furnizorul va furniza în mod activ datele brute sau nu? Cine va acționa ca experți în domeniu și cine îi va angaja fie ca angajați, fie ca antreprenori independenți?
Studii De Caz
Iată câteva exemple specifice de studii de caz care abordează modul în care adnotările și etichetarea datelor funcționează cu adevărat pe teren. La Shaip, avem grijă să oferim cele mai înalte niveluri de calitate și rezultate superioare în adnotarea și etichetarea datelor.
O mare parte din discuțiile de mai sus despre realizările standard pentru adnotarea și etichetarea datelor dezvăluie modul în care abordăm fiecare proiect și ce oferim companiilor și părților interesate cu care lucrăm.
Materiale de studiu de caz care vor demonstra cum funcționează:

Într-un proiect de licențiere a datelor clinice, echipa Shaip a procesat peste 6,000 de ore de audio, eliminând toate informațiile de sănătate protejate (PHI) și lăsând conținutul compatibil HIPAA pentru modelele de recunoaștere a vorbirii din domeniul sănătății.
În acest tip de cazuri, criteriile și clasificarea realizărilor sunt cele mai importante. Datele brute sunt sub formă de audio și este nevoie de de-identificarea părților. De exemplu, în utilizarea analizei NER, scopul dublu este de-identificarea și adnotarea conținutului.
Un alt studiu de caz presupune o aprofundare date conversaționale de antrenament AI proiect pe care l-am finalizat cu 3,000 de lingviști care lucrează pe o perioadă de 14 săptămâni. Acest lucru a condus la producerea de date de instruire în 27 de limbi, pentru a dezvolta asistenți digitali multilingvi capabili să gestioneze interacțiunile umane într-o selecție largă de limbi materne.
În acest studiu de caz particular, necesitatea de a aduce persoana potrivită pe scaunul potrivit a fost evidentă. Numărul mare de experți în domeniu și operatori de introducere a conținutului a însemnat că era nevoie de organizare și simplificare procedurală pentru a duce proiectul la bun sfârșit pe o anumită cronologie. Echipa noastră a reușit să depășească standardul industriei cu o marjă largă, prin optimizarea colectării datelor și a proceselor ulterioare.
Alte tipuri de studii de caz implică lucruri precum antrenarea botului și adnotarea textului pentru învățarea automată. Din nou, într-un format text, este încă important să tratați părțile identificate în conformitate cu legile de confidențialitate și să sortați datele brute pentru a obține rezultatele vizate.
Cu alte cuvinte, lucrând pe mai multe tipuri și formate de date, Shaip a demonstrat același succes vital prin aplicarea acelorași metode și principii atât pentru datele brute, cât și pentru scenariile de afaceri de licențiere a datelor.