
Te-ai întrebat vreodată cum se trezesc chatboții și asistenții virtuali când spui „Hei Siri” sau „Alexa”? Este din cauza colectării de enunțuri de text sau a cuvintelor declanșate încorporate în software-ul care activează sistemul de îndată ce aude cuvântul de trezire programat.
Cu toate acestea, procesul general de creare a sunetelor și a datelor de enunț nu este atât de simplu. Este un proces care trebuie efectuat cu tehnica potrivită pentru a obține rezultatele dorite. Prin urmare, acest blog vă va împărtăși calea spre crearea de enunțuri bune/cuvinte declanșatoare care funcționează perfect cu inteligența dvs. conversațională.
Ce sunt Enunțurile?
Enunțurile pot fi denumite expresii sau cuvinte declanșatoare utilizate pentru a activa un model inteligent artificial. Când modelul dvs. AI își detectează cuvântul de trezire, începe automat înregistrarea următoarei solicitări a utilizatorului și răspunde cu o acțiune sau un răspuns adecvat.
Utterance folosește conceptul de învățare profundă pentru a învăța software-ul cum să recunoască cuvintele de trezire. Odată ce cuvântul de trezire activează software-ul, sistemul începe să capteze, să decodească și să deservească cererea. Când nu este utilizat, sistemul continuă să asculte pasiv cuvintele declanșatoare.
Pentru ca software-ul dvs. AI să obțină rezultate precise, este esențial să captați o multitudine de enunțuri diferite pentru fiecare intenție. Ajută la o pregătire mai bună pentru modelul AI.
[Citește și: Ai vrea să știi cum te înțeleg Siri și Alexa?]
Puncte de reținut la crearea unui depozit de enunțuri
Acum că știm că instruirea este importantă pentru modelele AI, următorul lucru pe care trebuie să-l știm este cum să furnizezi enunțuri modelelor AI. De obicei, un depozit de enunțuri este creat pentru a antrena AI conversaționale.
Cu toate acestea, există diverse lucruri de reținut atunci când construiți depozite de enunțuri. Următoarele sunt lucrurile de luat în considerare:
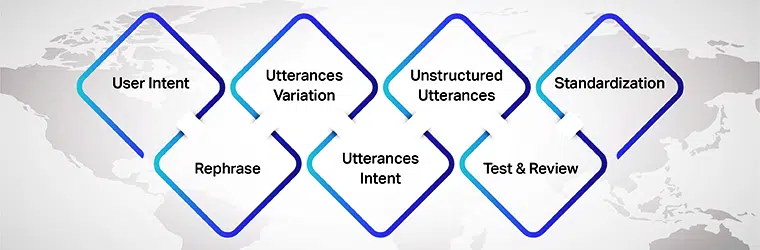
Intenția utilizatorului
În primul rând, atunci când pregătiți enunțuri pentru modelul dvs. AI, asigurați-vă că înțelegeți intenția utilizatorului pentru care dezvoltați seturile de date. Trebuie să vă dați seama de diferitele enunțuri pe care utilizatorii le pot introduce în timp ce conversează cu modelul AI.
Variația enunțurilor
Variațiile sunt o parte esențială a acestui proces, deoarece cu cât mai multe variații pentru fiecare intenție, cu atât vei obține rezultate mai bune. Așadar, asigurați-vă că creați mai multe variante ale enunțurilor utilizatorului. O poți face prin
- Crearea de propoziții scurte, medii și mari pentru aceleași propoziții.
- Schimbarea cuvintelor și a lungimii propozițiilor.
- Folosind cuvinte unice.
- Pluralizarea propozițiilor.
- Amestecând gramatica.



