

Ce sunt modelele lingvistice mari?
Modelele de limbaj mari (LLM) sunt sisteme avansate de inteligență artificială (AI) concepute pentru a procesa, înțelege și genera text asemănător omului. Acestea se bazează pe tehnici de învățare profundă și sunt instruite pe seturi de date masive, care conțin de obicei miliarde de cuvinte din diverse surse, cum ar fi site-uri web, cărți și articole. Această pregătire extinsă permite LLM-urilor să înțeleagă nuanțele de limbă, gramatică, context și chiar unele aspecte ale cunoștințelor generale.
Unele LLM populare, cum ar fi GPT-3 de la OpenAI, folosesc un tip de rețea neuronală numită transformator, care le permite să gestioneze sarcini de limbaj complexe cu o competență remarcabilă. Aceste modele pot îndeplini o gamă largă de sarcini, cum ar fi:
- Răspunzând la întrebări
- Rezumat text
- Traducerea limbilor
- Generarea de conținut
- Chiar și implicarea în conversații interactive cu utilizatorii
Pe măsură ce LLM-urile continuă să evolueze, ele dețin un potențial mare pentru îmbunătățirea și automatizarea diferitelor aplicații din industrii, de la servicii pentru clienți și crearea de conținut până la educație și cercetare. Cu toate acestea, ele ridică și preocupări etice și societale, cum ar fi comportamentul părtinitor sau utilizarea abuzivă, care trebuie abordate pe măsură ce tehnologia avansează.

Exemple populare de modele lingvistice mari
Iată câteva exemple proeminente de LLM-uri utilizate pe scară largă în diferite verticale din industrie:
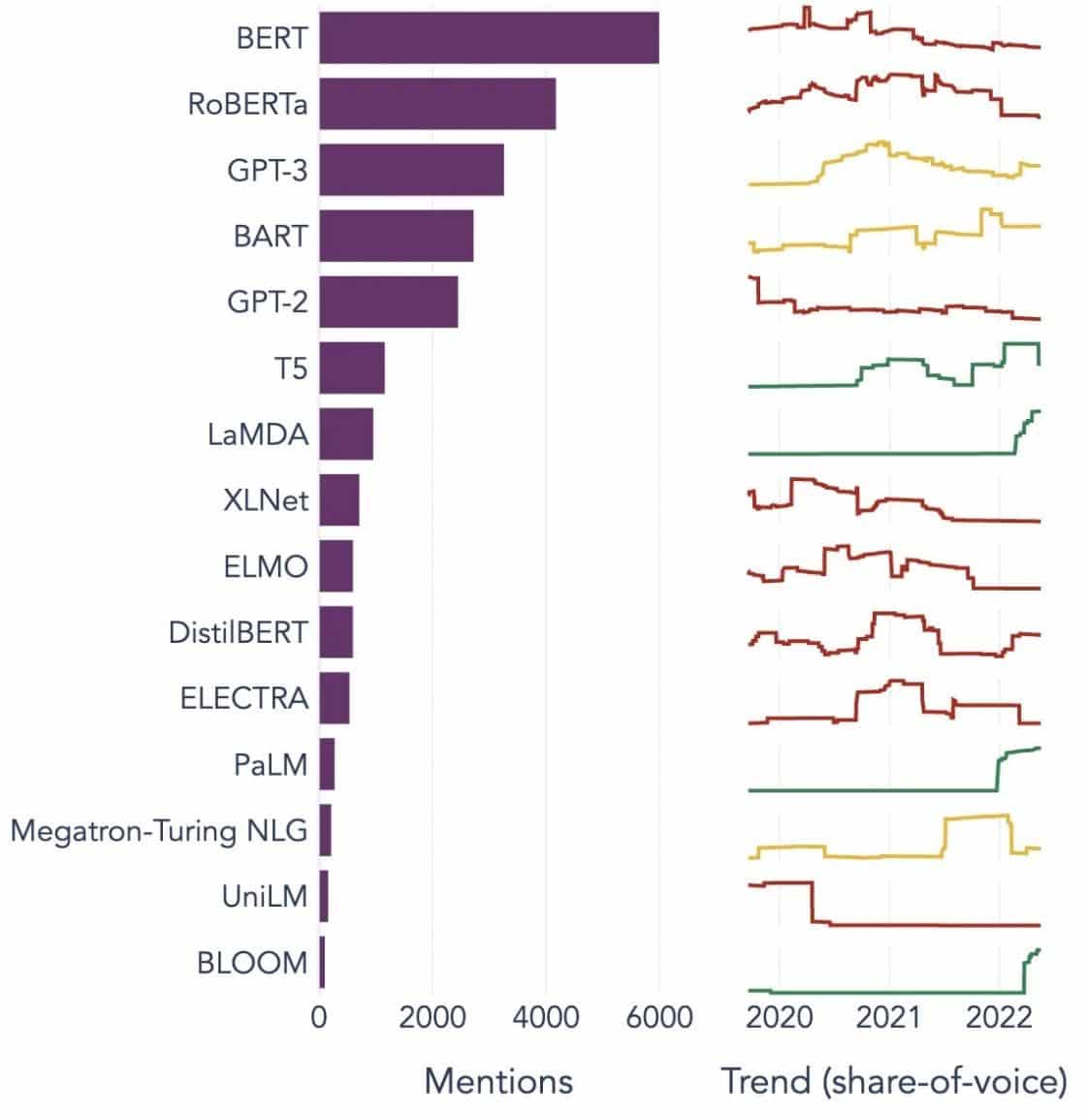
Imagine Sursa: Spre știința datelor
Cum sunt instruiți modelele LLM?
Formarea modelelor de limbaj mari (LLM) este o performanță care implică câțiva pași cruciali. Iată o prezentare simplificată, pas cu pas, a procesului:
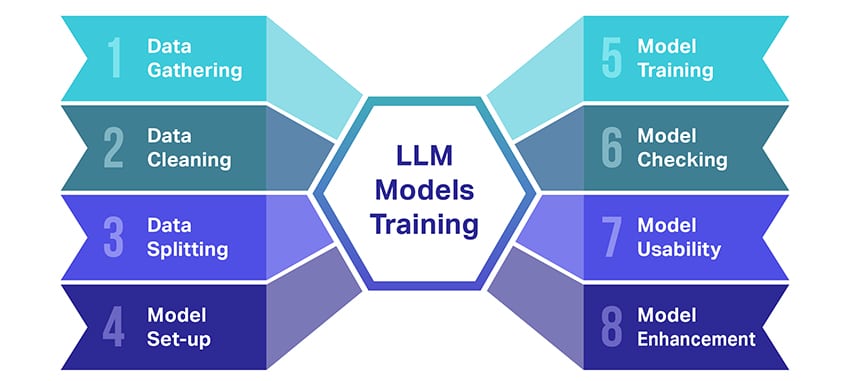
- Colectarea datelor text: Formarea unui LLM începe cu colectarea unei cantități mari de date text. Aceste date pot proveni de la cărți, site-uri web, articole sau platforme de social media. Scopul este de a surprinde diversitatea bogată a limbajului uman.
- Curățarea datelor: Datele de text brut sunt apoi ordonate într-un proces numit preprocesare. Aceasta include sarcini precum eliminarea caracterelor nedorite, împărțirea textului în părți mai mici numite jetoane și introducerea totul într-un format cu care modelul poate funcționa.
- Împărțirea datelor: Apoi, datele curate sunt împărțite în două seturi. Un set, datele de antrenament, va fi folosit pentru a antrena modelul. Celălalt set, datele de validare, va fi folosit ulterior pentru a testa performanța modelului.
- Configurarea modelului: Structura LLM, cunoscută sub numele de arhitectură, este apoi definită. Aceasta implică selectarea tipului de rețea neuronală și decizia asupra diferiților parametri, cum ar fi numărul de straturi și unități ascunse din rețea.
- Antrenarea modelului: Acum începe antrenamentul propriu-zis. Modelul LLM învață analizând datele de antrenament, făcând predicții pe baza a ceea ce a învățat până acum și apoi ajustând parametrii interni pentru a reduce diferența dintre predicțiile sale și datele reale.
- Verificarea modelului: Învățarea modelului LLM este verificată folosind datele de validare. Acest lucru vă ajută să vedeți cât de bine funcționează modelul și să modificați setările modelului pentru o performanță mai bună.
- Utilizarea Modelului: După instruire și evaluare, modelul LLM este gata de utilizare. Acum poate fi integrat în aplicații sau sisteme în care va genera text pe baza noilor intrări pe care le-a dat.
- Îmbunătățirea modelului: În sfârșit, există întotdeauna loc de îmbunătățire. Modelul LLM poate fi rafinat și mai mult în timp, folosind date actualizate sau ajustând setările pe baza feedback-ului și a utilizării în lumea reală.
Amintiți-vă, acest proces necesită resurse de calcul semnificative, cum ar fi unități de procesare puternice și stocare mare, precum și cunoștințe specializate în învățarea automată. De aceea, de obicei este realizat de organizații de cercetare dedicate sau companii cu acces la infrastructura și expertiza necesară.
LLM se bazează pe învățarea supravegheată sau nesupravegheată?
Modelele de limbaj mari sunt de obicei antrenate folosind o metodă numită învățare supravegheată. În termeni simpli, asta înseamnă că învață din exemple care le arată răspunsurile corecte.
 Imaginează-ți că înveți un copil cuvinte arătându-i imagini. Le arăți o imagine a unei pisici și spui „pisica”, iar ei învață să asocieze acea imagine cu cuvântul. Așa funcționează învățarea supravegheată. Modelului i se oferă mult text („imagini”) și rezultatele corespunzătoare („cuvinte”) și învață să le potrivească.
Imaginează-ți că înveți un copil cuvinte arătându-i imagini. Le arăți o imagine a unei pisici și spui „pisica”, iar ei învață să asocieze acea imagine cu cuvântul. Așa funcționează învățarea supravegheată. Modelului i se oferă mult text („imagini”) și rezultatele corespunzătoare („cuvinte”) și învață să le potrivească.
Așadar, dacă alimentați un LLM cu o propoziție, acesta încearcă să prezică următorul cuvânt sau frază pe baza a ceea ce a învățat din exemple. În acest fel, învață cum să genereze text care are sens și se potrivește contextului.
Acestea fiind spuse, uneori LLM-urile folosesc și un pic de învățare nesupravegheată. Este ca și cum ai lăsa copilul să exploreze o cameră plină de jucării diferite și să învețe singur despre ele. Modelul analizează datele neetichetate, modelele de învățare și structurile fără a primi răspunsurile „corecte”.
Învățarea supravegheată utilizează date care au fost etichetate cu intrări și ieșiri, spre deosebire de învățarea nesupravegheată, care nu utilizează date de ieșire etichetate.
Pe scurt, LLM-urile sunt instruite în principal folosind învățarea supravegheată, dar pot folosi și învățarea nesupravegheată pentru a-și îmbunătăți capacitățile, cum ar fi pentru analiza exploratorie și reducerea dimensionalității.
Care este volumul de date (în GB) necesar pentru formarea unui model de limbă mare?
Lumea posibilităților pentru recunoașterea datelor de vorbire și aplicațiile de voce este imensă și sunt utilizate în mai multe industrii pentru o multitudine de aplicații.
Formarea unui model de limbă mare nu este un proces unic, mai ales când vine vorba de datele necesare. Depinde de o grămadă de lucruri:
- Designul modelului.
- Ce treabă trebuie să facă?
- Tipul de date pe care le utilizați.
- Cât de bine vrei să funcționeze?
Acestea fiind spuse, formarea LLM-urilor necesită de obicei o cantitate masivă de date text. Dar despre cât de masiv vorbim? Ei bine, gândiți-vă mult dincolo de gigaocteți (GB). De obicei, ne uităm la terabytes (TB) sau chiar petabytes (PB) de date.
Luați în considerare GPT-3, unul dintre cele mai mari LLM-uri din jur. Este antrenat pe 570 GB de date text. LLM-urile mai mici ar putea avea nevoie de mai puțin – poate 10-20 GB sau chiar 1 GB de gigaocteți – dar este încă mult.

Dar nu este vorba doar de dimensiunea datelor. Calitatea conteaza si ea. Datele trebuie să fie curate și variate pentru a ajuta modelul să învețe eficient. Și nu puteți uita de alte piese cheie ale puzzle-ului, cum ar fi puterea de calcul de care aveți nevoie, algoritmii pe care îi folosiți pentru antrenament și configurația hardware pe care o aveți. Toți acești factori joacă un rol important în formarea unui LLM.
Ascensiunea modelelor lingvistice mari: de ce contează
LLM-urile nu mai sunt doar un concept sau un experiment. Aceștia joacă din ce în ce mai mult un rol esențial în peisajul nostru digital. Dar de ce se întâmplă asta? Ce face aceste LLM-uri atât de importante? Să analizăm câțiva factori cheie.
Măiestrie în imitarea textului uman
LLM-urile au transformat modul în care gestionăm sarcinile bazate pe limbaj. Construite folosind algoritmi robusti de învățare automată, aceste modele sunt echipate cu capacitatea de a înțelege nuanțele limbajului uman, inclusiv contextul, emoția și chiar sarcasmul, într-o oarecare măsură. Această capacitate de a imita limbajul uman nu este o simplă noutate, ci are implicații semnificative.
Abilitățile avansate de generare de text ale LLM-urilor pot îmbunătăți totul, de la crearea de conținut până la interacțiunile cu serviciul clienți.
Imaginați-vă că puteți pune o întrebare complexă unui asistent digital și puteți obține un răspuns care nu numai că are sens, dar este și coerent, relevant și oferit pe un ton conversațional. Aceasta este ceea ce permite LLM-urile. Acestea alimentează o interacțiune om-mașină mai intuitivă și mai captivantă, îmbogățesc experiențele utilizatorilor și democratizează accesul la informații.
Putere de calcul accesibilă
Creșterea LLM nu ar fi fost posibilă fără dezvoltări paralele în domeniul calculului. Mai precis, democratizarea resurselor de calcul a jucat un rol semnificativ în evoluția și adoptarea LLM-urilor.
Platformele bazate pe cloud oferă acces fără precedent la resurse de calcul de înaltă performanță. În acest fel, chiar și organizațiile la scară mică și cercetătorii independenți pot antrena modele sofisticate de învățare automată.
Mai mult, îmbunătățirile aduse unităților de procesare (cum ar fi GPU-urile și TPU-urile), combinate cu creșterea calculului distribuit, au făcut posibilă antrenarea modelelor cu miliarde de parametri. Această accesibilitate sporită a puterii de calcul permite creșterea și succesul LLM-urilor, conducând la mai multe inovații și aplicații în domeniu.
Schimbarea preferințelor consumatorilor
Consumatorii de astăzi nu vor doar răspunsuri; doresc interacțiuni captivante și care se pot identifica. Pe măsură ce tot mai mulți oameni cresc folosind tehnologia digitală, este evident că nevoia de tehnologie care se simte mai naturală și mai asemănătoare omului crește. LLM-urile oferă o oportunitate de neegalat de a îndeplini aceste așteptări. Prin generarea de text asemănător omului, aceste modele pot crea experiențe digitale captivante și dinamice, care pot crește satisfacția și loialitatea utilizatorilor. Fie că este vorba de chatbot AI care oferă servicii pentru clienți sau de asistenți vocali care oferă actualizări de știri, LLM-urile inaugurează o eră a AI care ne înțelege mai bine.
Mina de aur a datelor nestructurate
Datele nestructurate, cum ar fi e-mailurile, postările pe rețelele sociale și recenziile clienților, sunt o comoară de informații. Se estimează că s-a terminat 80% a datelor întreprinderii este nestructurată și crește cu o rată de 55% pe an. Aceste date sunt o mină de aur pentru companii dacă sunt utilizate în mod corespunzător.
LLM-urile intră în joc aici, cu capacitatea lor de a procesa și de a înțelege astfel de date la scară. Aceștia pot gestiona sarcini precum analiza sentimentelor, clasificarea textului, extragerea informațiilor și multe altele, oferind astfel informații valoroase.
Fie că este vorba de identificarea tendințelor din postările pe rețelele sociale sau de evaluarea sentimentului clienților din recenzii, LLM-urile ajută companiile să navigheze în cantitatea mare de date nestructurate și să ia decizii bazate pe date.
Piața NLP în expansiune
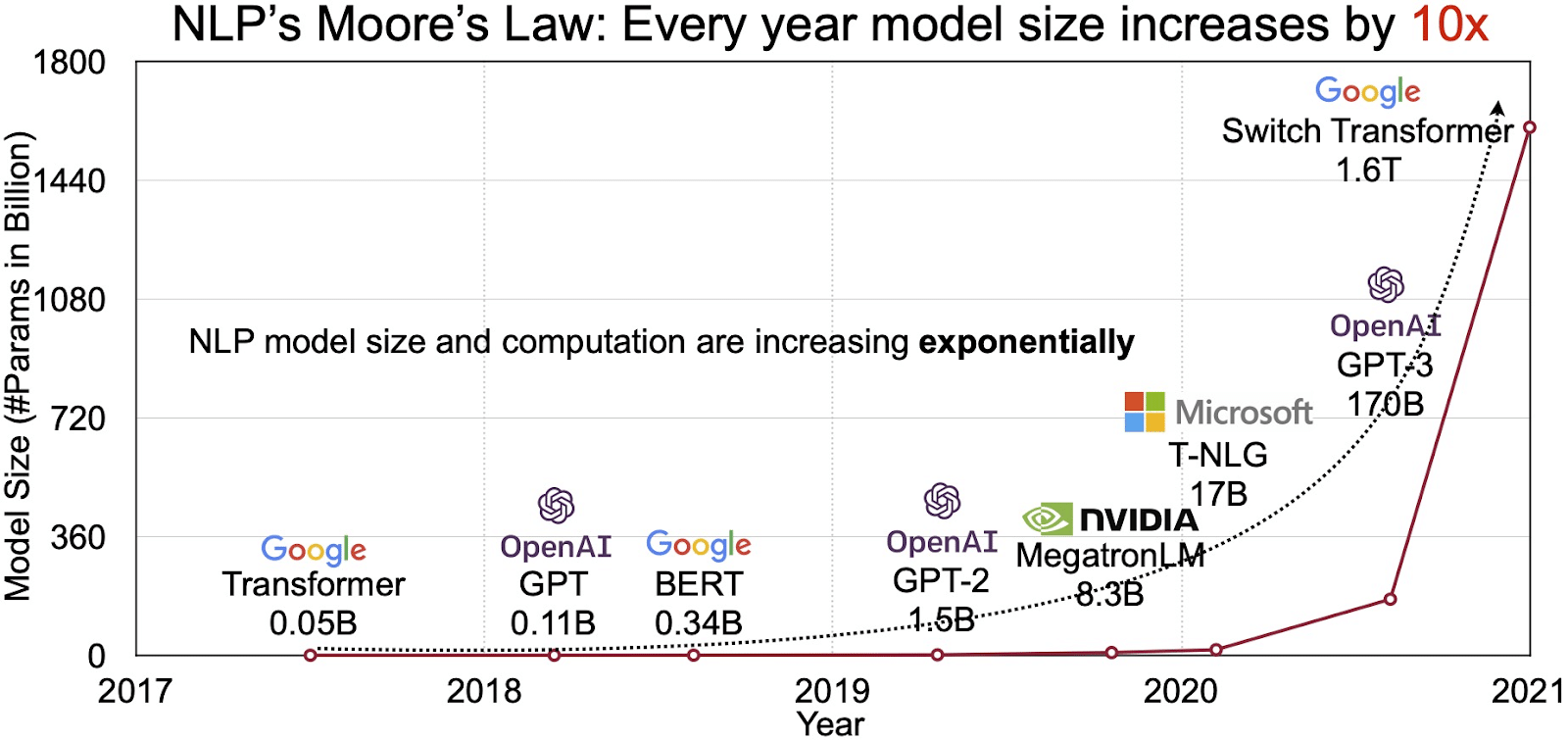
Potențialul LLM se reflectă în piața în creștere rapidă a procesării limbajului natural (NLP). Analistii proiecteaza ca piata NLP sa se extinda 11 miliarde de dolari în 2020 până la peste 35 de miliarde de dolari până în 2026. Dar nu doar dimensiunea pieței se extinde. Modelele în sine cresc și ele, atât ca dimensiune fizică, cât și ca număr de parametri pe care îi gestionează. Evoluția LLM-urilor de-a lungul anilor, așa cum se vede în figura de mai jos (sursa imaginii: link), subliniază complexitatea și capacitatea crescândă a acestora.
Cazuri de utilizare populare ale modelelor de limbaj mari
Iată câteva dintre cazurile de utilizare de top și cele mai răspândite ale LLM:
- Generarea textului în limbaj natural: Modelele de limbaj mari (LLM) combină puterea inteligenței artificiale și a lingvisticii computaționale pentru a produce în mod autonom texte în limbaj natural. Acestea pot răspunde nevoilor diverse ale utilizatorilor, cum ar fi redactarea articolelor, crearea de melodii sau implicarea în conversații cu utilizatorii.
- Traducerea prin mașini: LLM-urile pot fi utilizate eficient pentru a traduce text între orice pereche de limbi. Aceste modele exploatează algoritmi de învățare profundă, cum ar fi rețelele neuronale recurente, pentru a înțelege structura lingvistică atât a limbii sursă, cât și a limbii țintă, facilitând astfel traducerea textului sursă în limba dorită.
- Crearea conținutului original: LLM-urile au deschis căi pentru ca mașinile să genereze conținut coeziv și logic. Acest conținut poate fi folosit pentru a crea postări de blog, articole și alte tipuri de conținut. Modelele profită de experiența lor profundă de învățare profundă pentru a formata și structura conținutul într-un mod nou și ușor de utilizat.
- Analiza sentimentelor: O aplicație interesantă a modelelor de limbaj mari este analiza sentimentelor. În aceasta, modelul este antrenat să recunoască și să clasifice stările emoționale și sentimentele prezente în textul adnotat. Software-ul poate identifica emoții precum pozitivitatea, negativitatea, neutralitatea și alte sentimente complicate. Acest lucru poate oferi informații valoroase asupra feedback-ului clienților și opiniilor despre diverse produse și servicii.
- Înțelegerea, rezumarea și clasificarea textului: LLM-urile stabilesc o structură viabilă pentru software-ul AI pentru a interpreta textul și contextul acestuia. Instruind modelului să înțeleagă și să examineze cantități mari de date, LLM-urile permit modelelor AI să înțeleagă, să rezume și chiar să clasifice textul în diverse forme și modele.
- Răspunzând la întrebări: Modelele de limbaj mari echipează sistemele de răspuns la întrebări (QA) cu capacitatea de a percepe și de a răspunde cu acuratețe la interogarea în limbaj natural a unui utilizator. Exemple populare ale acestui caz de utilizare includ ChatGPT și BERT, care examinează contextul unei interogări și parcurg o colecție vastă de texte pentru a oferi răspunsuri relevante la întrebările utilizatorilor.

Etichetarea părții de vorbire (POS).
Cuvintele din propoziții sunt etichetate cu funcția lor gramaticală, cum ar fi verbe, substantive, adjective etc. Acest proces ajută modelul să înțeleagă gramatica și legăturile dintre cuvinte.

Recunoașterea entității denumite (NER)
Sunt marcate entitățile numite, cum ar fi organizațiile, locațiile și persoanele dintr-o propoziție. Acest exercițiu ajută modelul în interpretarea semnificațiilor semantice ale cuvintelor și frazelor și oferă răspunsuri mai precise.

Analiza sentimentelor
Datelor text li se atribuie etichete de sentiment precum pozitive, neutre sau negative, ajutând modelul să înțeleagă nuanța emoțională a propozițiilor. Este deosebit de util în răspunsul la întrebările care implică emoții și opinii.
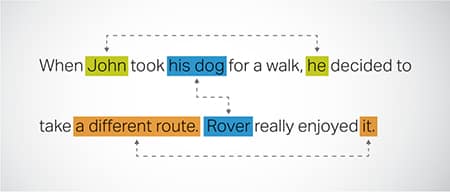
Rezoluția coreferenței
Identificarea și rezolvarea cazurilor în care se face referire la aceeași entitate în diferite părți ale unui text. Acest pas ajută modelul să înțeleagă contextul propoziției, conducând astfel la răspunsuri coerente.
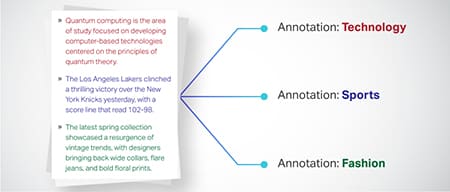
Clasificarea textului
Datele text sunt clasificate în grupuri predefinite, cum ar fi recenzii despre produse sau articole de știri. Acest lucru ajută modelul să discerne genul sau subiectul textului, generând răspunsuri mai pertinente.
Oferta lui Shaip
Shaip oferă o gamă largă de servicii pentru a ajuta organizațiile să gestioneze, să analizeze și să profite la maximum de datele lor.
Data Web-Scraping
Un serviciu cheie oferit de Shaip este data scraping. Aceasta implică extragerea datelor din adrese URL specifice domeniului. Folosind instrumente și tehnici automate, Shaip poate colecta rapid și eficient volume mari de date de pe diverse site-uri web, manuale de produse, documentație tehnică, forumuri online, recenzii online, date despre serviciul clienți, documente de reglementare a industriei etc. Acest proces poate fi de neprețuit pentru companii atunci când culegând date relevante și specifice dintr-o multitudine de surse.

Traducere automată
Dezvoltați modele folosind seturi extinse de date multilingve asociate cu transcripții corespunzătoare pentru traducerea textului în diferite limbi. Acest proces ajută la demontarea obstacolelor lingvistice și promovează accesibilitatea informațiilor.
Extragerea și crearea taxonomiei
Shaip poate ajuta la extragerea și crearea taxonomiei. Aceasta implică clasificarea și clasificarea datelor într-un format structurat care reflectă relațiile dintre diferitele puncte de date. Acest lucru poate fi deosebit de util pentru companii în organizarea datelor, făcându-le mai accesibile și mai ușor de analizat. De exemplu, într-o afacere de comerț electronic, datele despre produse pot fi clasificate în funcție de tipul produsului, marcă, preț etc., facilitând navigarea clienților în catalogul de produse.
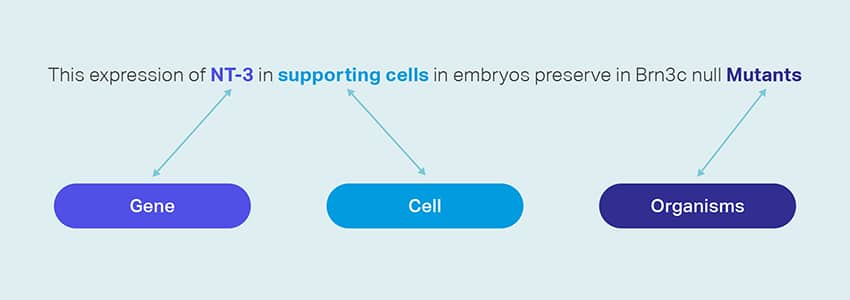
Colectare de date
Serviciile noastre de colectare a datelor oferă date critice din lumea reală sau sintetice, necesare pentru antrenarea algoritmilor generativi de inteligență artificială și pentru îmbunătățirea acurateței și eficacității modelelor dvs. Datele sunt imparțial, obținute din punct de vedere etic și responsabil, ținând cont de confidențialitatea și securitatea datelor.

Întrebări și răspunsuri
Răspunsul la întrebări (QA) este un subdomeniu al procesării limbajului natural axat pe răspunsul automat la întrebări în limbajul uman. Sistemele de asigurare a calității sunt instruite pe text și cod extins, permițându-le să gestioneze diferite tipuri de întrebări, inclusiv cele de fapt, definiționale și bazate pe opinii. Cunoștințele domeniului sunt esențiale pentru dezvoltarea modelelor QA adaptate unor domenii specifice, cum ar fi asistența pentru clienți, asistența medicală sau lanțul de aprovizionare. Cu toate acestea, abordările generative QA permit modelelor să genereze text fără cunoștințe de domeniu, bazându-se exclusiv pe context.
Echipa noastră de specialiști poate studia meticulos documente sau manuale cuprinzătoare pentru a genera perechi Întrebare-Răspuns, facilitând crearea de IA generativă pentru afaceri. Această abordare poate aborda în mod eficient întrebările utilizatorilor prin extragerea de informații relevante dintr-un corpus extins. Experții noștri certificați asigură producerea de perechi de întrebări și răspunsuri de cea mai bună calitate, care se întind pe diverse subiecte și domenii.

Rezumarea textului
Specialiștii noștri sunt capabili să distileze conversații cuprinzătoare sau dialoguri lungi, oferind rezumate succinte și perspicace din date text extinse.

Generarea textului
Antrenați modele folosind un set larg de date de text în diverse stiluri, cum ar fi articole de știri, ficțiune și poezie. Aceste modele pot genera apoi diferite tipuri de conținut, inclusiv articole de știri, intrări pe blog sau postări pe rețelele sociale, oferind o soluție rentabilă și care economisește timp pentru crearea de conținut.
Recunoaștere a vorbirii
Dezvoltați modele capabile să înțeleagă limbajul vorbit pentru diverse aplicații. Acestea includ asistenți activați prin voce, software de dictare și instrumente de traducere în timp real. Procesul implică utilizarea unui set cuprinzător de date compus din înregistrări audio ale limbajului vorbit, asociate cu transcrierile lor corespunzătoare.

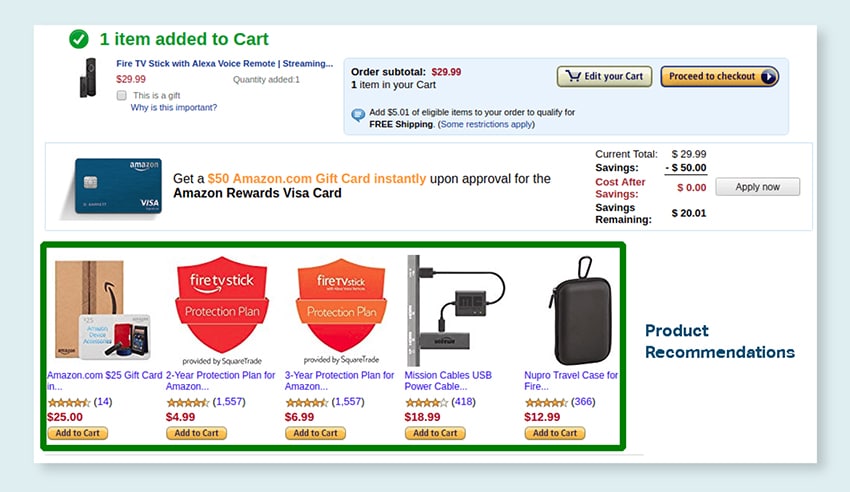
Recomandări de produs
Dezvoltați modele folosind seturi de date extinse ale istoricului de cumpărare a clienților, inclusiv etichete care indică produsele pe care clienții sunt înclinați să le cumpere. Scopul este de a oferi sugestii precise clienților, crescând astfel vânzările și sporind satisfacția clienților.
Subtitrărea imaginii
Revoluționați-vă procesul de interpretare a imaginilor cu serviciul nostru de ultimă generație, bazat pe AI. Infuzăm vitalitate imaginilor producând descrieri precise și semnificative din punct de vedere contextual. Acest lucru deschide calea pentru posibilități inovatoare de implicare și interacțiune cu conținutul dvs. vizual pentru publicul dvs.

Servicii de instruire Text-to-Speech
Oferim un set extins de date compus din înregistrări audio ale vorbirii umane, ideale pentru antrenarea modelelor AI. Aceste modele sunt capabile să genereze voci naturale și captivante pentru aplicațiile dvs., oferind astfel o experiență sonoră distinctivă și captivantă pentru utilizatorii dvs.



