
AI, Big Data și Machine Learning continuă să influențeze factorii de decizie, companiile, știința, casele media și o varietate de industrii din întreaga lume. Rapoartele sugerează că rata globală de adoptare a AI este în prezent la 35% în 2022 – o creștere uimitoare de 4% față de 2021. Se pare că încă 42% dintre companii explorează numeroasele beneficii ale AI pentru afacerea lor.
Alimentarea numeroaselor inițiative AI și Invatare mecanica soluțiile sunt date. AI poate fi la fel de bună decât datele care alimentează algoritmul. Datele de calitate scăzută ar putea duce la rezultate de calitate scăzută și previziuni inexacte.
Deși s-a acordat multă atenție dezvoltării soluțiilor ML și AI, lipsește conștientizarea a ceea ce se califică drept set de date de calitate. În acest articol, navigăm în cronologia date de formare AI de calitate și să identifice viitorul AI printr-o înțelegere a colectării de date și a instruirii.
Definiția AI training data
Când construiți o soluție ML, cantitatea și calitatea setului de date de antrenament contează. Sistemul ML nu numai că necesită volume mari de date de antrenament dinamice, imparțial și valoroase, dar are nevoie și de multe.
Dar ce sunt datele de antrenament AI?
Datele de antrenament AI sunt o colecție de date etichetate utilizate pentru a antrena algoritmul ML pentru a face predicții precise. Sistemul ML încearcă să recunoască și să identifice modele, să înțeleagă relațiile dintre parametri, să ia deciziile necesare și să evalueze pe baza datelor de antrenament.
Luați exemplul mașinilor cu conducere autonomă, de exemplu. Setul de date de instruire pentru un model ML cu conducere autonomă ar trebui să includă imagini etichetate și videoclipuri cu mașini, pietoni, indicatoare stradale și alte vehicule.
Pe scurt, pentru a îmbunătăți calitatea algoritmului ML, aveți nevoie de cantități mari de date de antrenament bine structurate, adnotate și etichetate.
Importanța datelor de formare de calitate și evoluția acestora
Datele de antrenament de înaltă calitate sunt elementul cheie în dezvoltarea aplicațiilor AI și ML. Datele sunt colectate din diverse surse și prezentate într-o formă neorganizată, neadecvată pentru scopurile învățării automate. Datele de antrenament de calitate – etichetate, adnotate și etichetate – sunt întotdeauna într-un format organizat – ideal pentru antrenamentul ML.
Datele de antrenament de calitate fac ca sistemul ML să recunoască mai ușor obiectele și să le clasifice în funcție de caracteristici predeterminate. Setul de date ar putea produce rezultate proaste pentru model dacă clasificarea nu este exactă.
Datele din primele zile ale instruirii AI
În ciuda faptului că AI domină lumea actuală a afacerilor și a cercetării, primele zile înainte de ML au dominat Inteligenta Artificiala a fost destul de diferit.
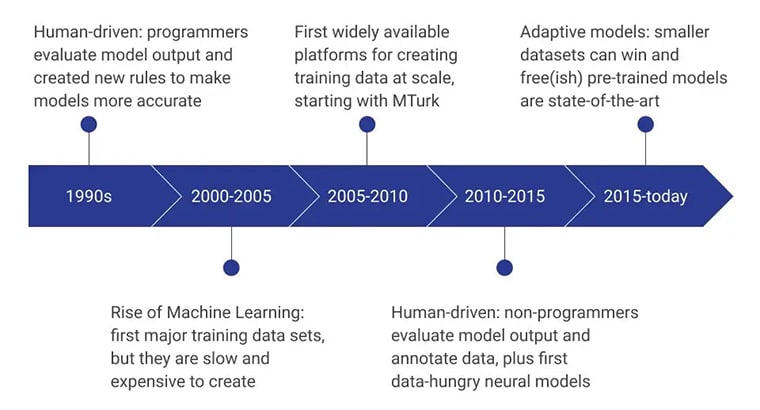
Etapele inițiale ale datelor de instruire AI au fost alimentate de programatori umani care au evaluat rezultatul modelului prin conceperea constantă de noi reguli care au făcut modelul mai eficient. În perioada 2000 – 2005, a fost creat primul set de date major și a fost un proces extrem de lent, dependent de resurse și costisitor. A dus la dezvoltarea la scară a seturi de date de instruire, iar MTurk de la Amazon a jucat un rol semnificativ în schimbarea percepțiilor oamenilor față de colectarea datelor. Simultan, etichetarea și adnotarea umană au luat amploare.
Următorii câțiva ani s-au concentrat pe non-programatori care creează și evaluează modelele de date. În prezent, accentul se pune pe modele pre-instruite dezvoltate folosind metode avansate de colectare a datelor de formare.
Cantitatea peste calitate
Când evaluau integritatea seturilor de date de antrenament AI pe vremuri, oamenii de știință s-au concentrat pe Cantitatea de date de antrenament AI peste calitate.
De exemplu, a existat o concepție greșită comună că bazele de date mari oferă rezultate precise. Volumul mare de date a fost considerat a fi un bun indicator al valorii datelor. Cantitatea este doar unul dintre factorii primari care determină valoarea setului de date – rolul calității datelor a fost recunoscut.
Conștientizarea că calitatea datelor a depins de caracterul complet al datelor, fiabilitatea, validitatea, disponibilitatea și oportunitatea crescută. Cel mai important, adecvarea datelor pentru proiect a determinat calitatea datelor colectate.
Limitări ale sistemelor AI timpurii din cauza datelor slabe de antrenament
Datele slabe de instruire, împreună cu lipsa sistemelor de calcul avansate, au fost unul dintre motivele mai multor promisiuni neîndeplinite ale sistemelor AI timpurii.
Din cauza lipsei de date de antrenament de calitate, soluțiile ML nu au putut identifica cu exactitate modelele vizuale care împiedică dezvoltarea cercetării neuronale. Deși mulți cercetători au identificat promisiunea recunoașterii limbajului vorbit, cercetarea sau dezvoltarea instrumentelor de recunoaștere a vorbirii nu s-a putut realiza datorită lipsei seturilor de date despre vorbire. Un alt obstacol major în calea dezvoltării instrumentelor AI de înaltă calitate a fost lipsa computerelor de capabilități de calcul și stocare.
Trecerea către date de formare de calitate
A existat o schimbare semnificativă în conștientizarea faptului că calitatea setului de date contează. Pentru ca sistemul ML să imite cu acuratețe inteligența umană și capacitățile de luare a deciziilor, trebuie să prospere cu date de antrenament de mare volum și de înaltă calitate.
Gândiți-vă la datele dvs. de ML ca la un sondaj – cu cât este mai mare eșantion de date mărimea, cu atât predicția este mai bună. Dacă eșantionul de date nu include toate variabilele, este posibil să nu recunoască modele sau să aducă concluzii inexacte.
Progrese în tehnologia AI și nevoia de date de antrenament mai bune
 Progresele în tehnologia AI cresc nevoia de date de formare de calitate.
Progresele în tehnologia AI cresc nevoia de date de formare de calitate.Înțelegerea faptului că datele de instruire mai bune cresc șansa unor modele ML fiabile a dat naștere la metodologii mai bune de colectare a datelor, adnotare și etichetare. Calitatea și relevanța datelor au afectat direct calitatea modelului AI.
 Progresele în tehnologia AI cresc nevoia de date de formare de calitate.
Progresele în tehnologia AI cresc nevoia de date de formare de calitate.O concentrare sporită pe calitatea și acuratețea datelor
Pentru ca modelul ML să înceapă să ofere rezultate precise, acesta este alimentat cu seturi de date de calitate care trec prin pași iterativi de rafinare a datelor.
De exemplu, o ființă umană ar putea fi capabilă să recunoască o anumită rasă de câine în câteva zile după ce a fost introdusă în rasă - prin imagini, videoclipuri sau în persoană. Oamenii se bazează din experiența lor și din informațiile aferente pentru a-și aminti și a extrage aceste cunoștințe atunci când este necesar. Cu toate acestea, nu funcționează la fel de ușor pentru o mașină. Aparatul trebuie să fie alimentat cu imagini clar adnotate și etichetate - sute sau mii - ale acelei rase și alte rase pentru ca acesta să facă legătura.
Un model AI prezice rezultatul corelând informațiile instruite cu informațiile prezentate în lumea reală. Algoritmul devine inutil dacă datele de antrenament nu includ informații relevante.
Importanța datelor de formare diverse și reprezentative
Diversitatea crescută a datelor crește, de asemenea, competența, reduce părtinirea și sporește reprezentarea echitabilă a tuturor scenariilor. Dacă modelul AI este antrenat folosind un set de date omogen, puteți fi sigur că noua aplicație va funcționa numai pentru un anumit scop și va servi unei anumite populații.Un set de date ar putea fi părtinitor față de o anumită populație, rasă, gen, alegere și opinii intelectuale, ceea ce ar putea duce la un model inexact.
Este important să ne asigurăm că întregul flux al procesului de colectare a datelor, inclusiv selectarea grupului de subiecte, curatarea, adnotarea și etichetarea, este adecvat divers, echilibrat și reprezentativ pentru populație.
 Diversitatea crescută a datelor crește, de asemenea, competența, reduce părtinirea și sporește reprezentarea echitabilă a tuturor scenariilor. Dacă modelul AI este antrenat folosind un set de date omogen, puteți fi sigur că noua aplicație va funcționa numai pentru un anumit scop și va servi unei anumite populații.
Diversitatea crescută a datelor crește, de asemenea, competența, reduce părtinirea și sporește reprezentarea echitabilă a tuturor scenariilor. Dacă modelul AI este antrenat folosind un set de date omogen, puteți fi sigur că noua aplicație va funcționa numai pentru un anumit scop și va servi unei anumite populații.Viitorul datelor de instruire AI
Succesul viitor al modelelor AI depinde de calitatea și cantitatea datelor de antrenament utilizate pentru antrenarea algoritmilor ML. Este esențial să recunoaștem că această relație dintre calitatea și cantitatea datelor este specifică sarcinii și nu are un răspuns cert.
În cele din urmă, adecvarea unui set de date de antrenament este definită de capacitatea sa de a funcționa bine în mod fiabil pentru scopul în care a fost construit.
Progrese în tehnicile de colectare și adnotare a datelor
Deoarece ML este sensibil la datele furnizate, este vital să eficientizați politicile de colectare și adnotare a datelor. Erorile în colectarea datelor, curatarea, denaturarea, măsurătorile incomplete, conținutul inexact, duplicarea datelor și măsurătorile eronate contribuie la o calitate insuficientă a datelor.
Colectarea automată a datelor prin data mining, web scraping și extragerea datelor deschide calea pentru o generare mai rapidă a datelor. În plus, seturile de date pre-ambalate acționează ca o tehnică de colectare a datelor de remediere rapidă.
Crowdsourcing-ul este o altă metodă inovatoare de colectare a datelor. În timp ce veridicitatea datelor nu poate fi garantată, este un instrument excelent pentru a aduna imaginea publică. În sfârșit, specializat de colectare a datelor experții furnizează, de asemenea, date obținute în scopuri specifice.
Accent crescut pe considerentele etice în datele de formare
Odată cu progresele rapide ale inteligenței artificiale, au apărut mai multe probleme etice, în special în colectarea datelor de formare. Unele considerații etice în colectarea datelor de formare includ consimțământul informat, transparența, părtinirea și confidențialitatea datelor.Deoarece datele includ acum totul, de la imagini faciale, amprente, înregistrări vocale și alte date biometrice esențiale, devine extrem de important să se asigure respectarea practicilor legale și etice pentru a evita procesele costisitoare și deteriorarea reputației.
Potențialul pentru o calitate și mai bună și date diverse de antrenament în viitor
Există un potențial imens pentru date de instruire de înaltă calitate și diverse în viitor. Datorită conștientizării calității datelor și disponibilității furnizorilor de date care răspund cerințelor de calitate ale soluțiilor AI.
Furnizorii de date actuali sunt abili în utilizarea tehnologiilor inovatoare pentru a obține din punct de vedere etic și legal cantități masive de seturi de date diverse. De asemenea, au echipe interne pentru etichetarea, adnotarea și prezentarea datelor personalizate pentru diferite proiecte ML.
 Odată cu progresele rapide ale inteligenței artificiale, au apărut mai multe probleme etice, în special în colectarea datelor de formare. Unele considerații etice în colectarea datelor de formare includ consimțământul informat, transparența, părtinirea și confidențialitatea datelor.
Odată cu progresele rapide ale inteligenței artificiale, au apărut mai multe probleme etice, în special în colectarea datelor de formare. Unele considerații etice în colectarea datelor de formare includ consimțământul informat, transparența, părtinirea și confidențialitatea datelor.Concluzie
Este important să colaborați cu furnizori de încredere, cu o înțelegere acută a datelor și a calității dezvolta modele de IA de vârf. Shaip este cea mai importantă companie de adnotare expertă în furnizarea de soluții de date personalizate care să răspundă nevoilor și obiectivelor dvs. de proiect AI. Colaborați cu noi și explorați competențele, angajamentul și colaborarea pe care le aducem la masă.


