
Inteligența artificială revoluționează industria muzicală, oferind instrumente automate de compoziție, mastering și performanță. Algoritmii de inteligență artificială generează compoziții noi, prezic hit-uri și personalizează experiența ascultătorului, transformând producția, distribuția și consumul de muzică. Această tehnologie emergentă prezintă atât oportunități interesante, cât și dileme etice provocatoare.
Modelele de învățare automată (ML) necesită date de antrenament pentru a funcționa eficient, deoarece un compozitor are nevoie de note muzicale pentru a scrie o simfonie. În lumea muzicii, unde melodia, ritmul și emoția se împletesc, importanța datelor de antrenament de calitate nu poate fi exagerată. Este coloana vertebrală a dezvoltării unor modele de ML muzicale robuste și precise pentru analiza predictivă, clasificarea genurilor sau transcrierea automată.
Data, sângele de viață al modelelor ML
Învățarea automată este în mod inerent bazată pe date. Aceste modele de calcul învață modele din date, permițându-le să facă predicții sau decizii. Pentru modelele muzicale ML, datele de antrenament vin adesea în piese muzicale digitalizate, versuri, metadate sau o combinație a acestor elemente. Calitatea, cantitatea și diversitatea acestor date au un impact semnificativ asupra eficienței modelului.

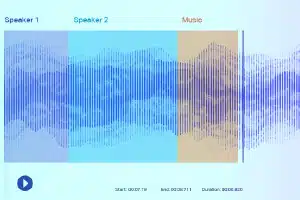
Etichetarea sunetului
Cu etichetarea sunetului, adnotatorii de date primesc o înregistrare și trebuie să separe toate sunetele necesare și să le eticheteze. De exemplu, acestea pot fi anumite cuvinte cheie sau sunetul unui anumit instrument muzical.

Clasificarea muzicii
Adnotatorii de date pot marca genuri sau instrumente în acest tip de adnotare audio. Clasificarea muzicii este foarte utilă pentru organizarea bibliotecilor muzicale și îmbunătățirea recomandărilor utilizatorilor.

Segmentarea nivelului fonetic
Etichetarea și clasificarea segmentelor fonetice pe formele de undă și spectrogramele înregistrărilor indivizilor care cântă acapella.
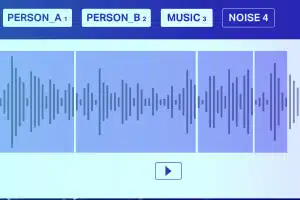
Clasificarea sunetului
Cu excepția tăcerii/zgomotului alb, un fișier audio constă în mod obișnuit din următoarele tipuri de sunet Vorbire, Bâmbăie, Muzică și Zgomot. Adnotați cu precizie notele muzicale pentru o precizie mai mare.
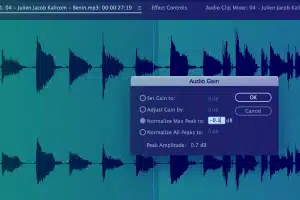
Captarea informațiilor metadate
Capturați informații importante, cum ar fi ora de începere, ora de sfârșit, ID-ul segmentului, nivelul sonorității, tipul de sunet primar, codul limbii, ID-ul difuzorului și alte convenții de transcriere etc.


