În lumea noastră digitală, companiile procesează zilnic tone de date. Datele mențin organizația în funcțiune și o ajută să ia decizii mai bine informate. Companiile sunt inundate de documente, de la angajați care creează altele noi până la documente care intră în organizație din diverse surse, cum ar fi e-mailuri, portaluri, facturi, chitanțe, cereri, propuneri, revendicări și multe altele.
Cu excepția cazului în care cineva examinează aceste documente, nu există nicio modalitate de a ști despre ce este vorba despre un anumit document sau cea mai bună modalitate de a-l procesa. Cu toate acestea, procesarea manuală a fiecărui document pentru a ști unde și cum ar trebui să fie stocat este dificilă.
Să explorăm clasificarea documentelor, să înțelegem de ce clasificarea documentelor este crucială pentru o afacere și să studiem modul în care Viziunea computerizată, Procesarea limbajului natural și Recunoașterea optică a caracterelor joacă un rol în Clasificarea Documentelor sau Procesarea documentelor.
Ce este clasificarea documentelor?
Sarcinile de clasificare manuală a documentelor pot fi un blocaj uriaș pentru multe companii, deoarece sunt consumatoare de timp, sunt predispuse la erori și consumă resurse. Când sunt utilizate modele de clasificare automată bazate pe NLP și ML, textul dintr-un document este identificat, etichetat și clasificat automat.
Sarcinile de clasificare a documentelor se bazează în general pe două clasificări: text și vizual. Clasificarea textului se bazează pe genul, tema sau tipul conținutului. Procesarea limbajului natural este folosit pentru a înțelege conceptul, emoțiile și contextul textului. Clasificarea vizuală se face pe baza elementelor structurale vizuale prezente în document utilizând sisteme de computer Vision și recunoaștere a imaginii.
De ce companiile necesită clasificarea documentelor?

Fiecare afacere, mare și mică, trebuie să se ocupe de documentație pentru a-și gestiona operațiunile de zi cu zi. Deoarece este imposibil să procesați manual fiecare document, este necesar să folosiți un sistem automat de clasificare a documentelor. Sistemul de clasificare a documentelor permite companiilor să organizeze conținutul și să îl facă disponibil oricând.
Clasificarea documentelor are mai multe cazuri de utilizare în diverse industrii, de la spitale la afaceri.
- Ajută companiile să automatizeze gestionarea și procesarea documentelor.
- Clasificarea documentelor este o sarcină banală și repetitivă, automatizarea procesului reduce erorile de procesare și îmbunătățește timpul de realizare.
- Automatizarea documentelor îmbunătățește, de asemenea, eficiența, fiabilitatea și scalabilitatea.
Clasificarea documentelor vs. Clasificarea textului
Clasificarea textului și clasificarea documentelor sunt uneori folosite în mod interschimbabil. Deși există o diferență foarte mică între cele două, este important să știm cum diferă.
Clasificarea textului este despre utilizarea tehnicilor de analiză a textului în documente bazate pe text. Textul poate fi clasificat la diferite niveluri, cum ar fi
| Nivel de propoziție | Nivelul subpropoziției |
|---|---|
| Clasificarea textului se bazează pe informațiile dintr-o singură propoziție. | Nivelul de subpropoziție atrage subexpresii din interiorul propozițiilor. |
| Nivelul paragrafului | Nivelul documentului |
|---|---|
| Extrage informațiile de bază sau cele mai critice dintr-un singur paragraf. | Desenați informații importante din întregul document. |
Clasificarea textului este un subset al clasificării documentelor care se ocupă în întregime de clasificarea textului în orice document dat. În timp ce clasificarea textului se ocupă numai de text, clasificarea documentelor este atât textuală, cât și vizuală. În clasificarea textului, doar textul este folosit pentru a clasifica, în timp ce, în clasificarea documentelor, documentul complet poate fi folosit pentru context.
Cum funcționează clasificarea documentelor?
Clasificarea documentelor se poate face folosind două metode: manuală și automată. În clasificarea manuală, un utilizator uman trebuie să revizuiască documentele, să găsească relații între concepte și să clasifice în consecință. În clasificarea automată a documentelor, se folosesc tehnici de învățare automată și de învățare profundă. Să dezvăluim metodele de clasificare a documentelor prin înțelegerea diferitelor tipuri de documente pe care le procesează o afacere.
Documente structurate
Un document conține date bine formatate, cu numerotare și fonturi consistente. Aspectul documentului este, de asemenea, consistent și nu are abateri. Construirea instrumentelor de clasificare pentru astfel de documente structurate este ușoară și previzibilă.
Documente nestructurate
Un document nestructurat are conținut prezentat într-un format nestructurat sau deschis. Exemplele includ scrisori, contracte și comenzi. Deoarece sunt inconsecvente, devine dificil să găsiți informații critice.

Tehnici de clasificare a documentelor?
Clasificarea automată a documentelor utilizează tehnici de învățare automată și procesare a limbajului natural pentru a simplifica, automatiza și accelera procesul de clasificare. Învățarea automată face clasificarea documentelor mai puțin greoaie, mai rapidă, mai precisă, scalabilă și imparțială.
Clasificarea documentelor se poate face folosind trei tehnici. Sunt
Tehnica bazată pe reguli
Tehnica bazată pe reguli se bazează pe modele și reguli lingvistice care oferă instrucțiuni modelului. Modelele sunt instruite pentru a identifica modele de limbaj, morfologie, sintaxă, semantică și multe altele pentru a eticheta textul. Această tehnică poate fi îmbunătățită constant, noi reguli adăugate și improvizate pentru a extrage informații precise. Cu toate acestea, această tehnică poate fi consumatoare de timp, nescalabilă și complexă.
Învățare supravegheată
Un set de etichete este definit în învățarea supravegheată, iar mai multe texte sunt etichetate manual, astfel încât sistemul de învățare automată să învețe să facă predicții precise. Algoritmul este antrenat manual pe un set de documente etichetate. Cu cât introduceți mai multe date în sistem, cu atât rezultatul este mai bun. De exemplu, dacă textul spune „Serviciul a fost accesibil”, eticheta ar trebui să fie sub „preț”. Odată ce antrenamentul modelului este complet, acesta poate prezice automat documente nevăzute.
Învățare fără supraveghere
În învățarea nesupravegheată, documentele similare sunt grupate în grupuri diferite. Această învățare nu necesită cunoștințe prealabile. Documentele sunt clasificate în funcție de fonturi, teme, șabloane și multe altele. Dacă regulile sunt predefinite, ajustate și perfecționate, acest model poate oferi clasificare cu acuratețe.
Procesul de clasificare a documentelor
Construirea unui algoritm de clasificare automată a documentelor implică învățare profundă și fluxuri de lucru de învățare automată.
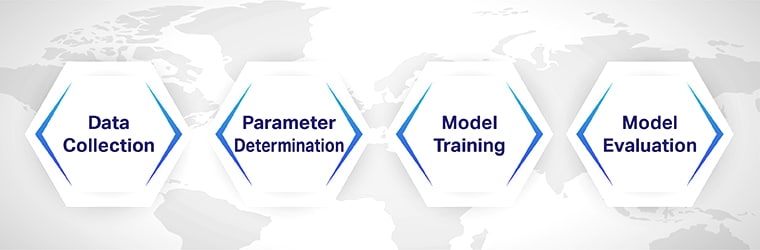
Pasul 1: Colectarea datelor
Colectare de date este poate cel mai important pas în instruirea algoritmilor de clasificare a documentelor. Este necesar să se adune documente din diverse categorii, astfel încât algoritmul să învețe cum să le clasifice.
De exemplu, dacă modelul dvs. trebuie să fie clasificat în cinci categorii diferite, trebuie să aveți un set de date care să conțină minimum 300 de documente per categorie.
De asemenea, asigurați-vă că setul de date pe care îl utilizați pentru antrenament este etichetat corect. Dacă setul de date este incorect, modelul pe care îl construiți va fi plin de probleme.
Pasul 2: Determinarea parametrilor
Înainte de a antrena modelul, trebuie să determinați parametrii pentru a antrena modelele de învățare automată. Valorile pe care le definiți în această etapă pot fi modificate pentru a face modelul mai precis și mai fiabil în predicțiile sale.
Pasul 3: Training model
După setarea parametrilor, modelul trebuie antrenat. Dacă tocmai ați început să dezvoltați modele, puteți încerca să utilizați seturi de date open-source în scopuri de instruire și testare.
Dacă modelul funcționează de obicei cu un algoritm de învățare automată, puteți să importați modelul sau să efectuați codare pe baza logicii algoritmului.
Pasul 4: Evaluarea modelului
Evaluarea modelului după antrenament este esențială pentru a spori eficacitatea și acuratețea acestuia. Începeți prin a împărți setul de date în două secțiuni mari, una pentru instruire și cealaltă pentru testare. Utilizați 70% din setul de date pentru antrenamentul modelului, iar restul, 30%, pentru testare și evaluare.
Cazuri de utilizare din viața reală
Clasificarea documentelor este folosită pentru a rezolva mai multe probleme de afaceri. Deși majoritatea cazurilor de utilizare nu sunt sarcini de clasificare, algoritmul este folosit pentru a rezolva mai multe probleme din viața reală.
Detectarea spamului
Clasificarea documentelor, în special clasificarea textului, este utilizată pentru a detecta spam-ul nedorit. Modelul este antrenat să detecteze fraze spam și frecvența acestora pentru a determina dacă mesajul este spam. De exemplu, detectorul de spam Gmail de la Google folosește tehnica de procesare a limbajului natural pentru a detecta cuvintele care apar frecvent în mesajele nedorite și pentru a arunca e-mailurile în folderul corect.
Analiza sentimentelor
Analiza sentimentelor prin ascultarea socială ajută companiile să-și înțeleagă clienții, opiniile și recenziile lor. Prin clasificarea recenziilor, feedback-ului și plângerilor și clasificându-le în funcție de natura lor emoțională, modelele bazate pe NLP ajută la analiza sentimentelor. Modelul este antrenat să extragă cuvinte care denotă sau au conotații pozitive sau negative.
Biletul sau clasificarea prioritară
Departamentul de servicii pentru clienți al oricărei companii întâmpină multe solicitări de servicii și bilete. Un instrument automat de clasificare a documentelor poate ajuta la trecerea prin volumul masiv de bilete. Folosind NLP, biletele prioritare pot fi direcționate către departamentul corect. Acest lucru îmbunătățește semnificativ viteza de rezoluție, procesare și service.
Recunoașterea obiectelor
Clasificarea automată a documentelor este, de asemenea, utilizată pentru a procesa cantități mari de date vizuale în documente prin clasificarea lor în funcție de categorii. Recunoașterea obiectelor este utilizată de obicei în comerțul electronic sau în unitățile de producție pentru a clasifica produsele.
Noțiuni introductive cu clasificarea documentelor cu ajutorul AI
Documentele conțin date critice pentru funcționarea afacerii. Documentele conțin informații valoroase care promovează operațiunile, serviciile și obiectivele de creștere ale unei organizații.
Cu toate acestea, clasificarea documentelor este o sarcină obositoare, dar necesară. Deoarece clasificarea documentelor este o provocare, mai ales dacă volumul este relativ mare, este necesar să existe un sistem automat de clasificare a documentelor.
Un model de clasificare a documentelor bazat pe inteligență artificială antrenat de algoritmi de învățare automată este eficient, rentabil, fără erori și precis. Dar procesul poate începe numai atunci când modelul pe care îl construiți este instruit pe seturi de date de calitate și etichetate cu precizie.
Shaip îți aduce seturi de date pre-etichetate care ajută la dezvoltarea unor modele de clasificare precise. Luați legătura cu noi și începeți imediat cu instrumentul dvs. de clasificare a documentelor.