Internetul a deschis ușile oamenilor care își exprimă liber opiniile, opiniile și sugestiile despre aproape orice din lume. social media, site-uri web și bloguri. Pe lângă faptul că își exprimă opiniile, oamenii (clienții) influențează și deciziile de cumpărare ale altora. Sentimentul, indiferent dacă este negativ sau pozitiv, este critic pentru orice afacere sau marcă preocupată de vânzările produselor sau serviciilor sale.
A ajuta companiile să mine comentariile pentru utilizare în afaceri este Procesarea limbajului natural. Una din patru afaceri are in plan să implementeze tehnologia NLP în următorul an pentru a-și putea lua deciziile de afaceri. Folosind analiza sentimentelor, NLP ajută companiile să obțină informații interpretabile din date brute și nestructurate.
minarea opiniei sau Analiza sentimentului este o tehnică de NLP folosită pentru a identifica sentimentul exact - pozitiv, negativ sau neutru – asociat cu comentarii și feedback. Cu ajutorul NLP, cuvintele cheie din comentarii sunt analizate pentru a determina cuvintele pozitive sau negative conținute în cuvântul cheie.
Sentimentele sunt punctate pe un sistem de scalare care atribuie scoruri de sentimente emoțiilor dintr-o bucată de text (determinând textul ca pozitiv sau negativ).
Ce este analiza multilingvă a sentimentelor?

După cum sugerează și numele, analiza sentimentelor multilingve este tehnica de realizare a scorurilor de sentiment pentru mai mult de o limbă. Cu toate acestea, nu este atât de simplu. Cultura, limba și experiențele noastre ne influențează foarte mult comportamentul și emoțiile de cumpărare. Fără o bună înțelegere a limbajului, contextului și culturii utilizatorului, este imposibil să înțelegem cu exactitate intențiile, emoțiile și interpretările utilizatorului.
În timp ce automatizarea este răspunsul la multe dintre problemele noastre moderne, traducere automată software-ul nu va putea prelua nuanțele limbajului, colocvialismele, subtilitățile și referințele culturale din comentarii și Comentarii despre produs se traduce. Instrumentul ML vă poate oferi o traducere, dar s-ar putea să nu fie util. Acesta este motivul pentru care este necesară analiza multilingvă a sentimentelor.
De ce este necesară analiza multilingvă a sentimentelor?
Majoritatea companiilor folosesc limba engleză ca mediu de comunicare, dar nu este folosită de majoritatea consumatorilor din întreaga lume.
Potrivit Ethnologue, aproximativ 13% din populația lumii vorbește engleza. În plus, British Council afirmă că aproximativ 25% din populația lumii are o înțelegere decentă a limbii engleze. Dacă aceste cifre sunt de crezut, atunci o mare parte a consumatorilor interacționează între ei și afacerea într-o altă limbă decât engleza.
Dacă scopul principal al companiilor este de a-și păstra intactă baza de clienți și de a atrage noi clienți, trebuie să înțeleagă îndeaproape opiniile clienților lor exprimate în limba materna. Revizuirea manuală a fiecărui comentariu sau traducerea lor în engleză este un proces greoi care nu va da rezultate eficiente.
O soluție durabilă este dezvoltarea multilingvului sisteme de analiză a sentimentelor care detectează și analizează opiniile, emoțiile și sugestiile clienților în rețelele sociale, forumuri, sondaje și multe altele.
Pași pentru a efectua analiza multilingvă a sentimentelor
Analiza sentimentelor, indiferent dacă într-o singură limbă sau mai multe limbi, este un proces care necesită aplicarea modelelor de învățare automată, procesare a limbajului natural și tehnici de analiză a datelor pentru extragere punctaj de sentiment multilingv din date.
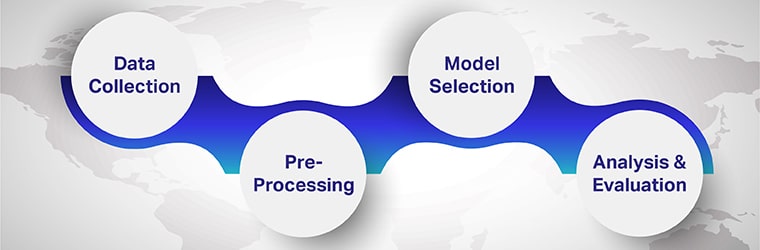
Pașii implicați în analiza sentimentelor multilingve sunt
Pasul 1: Colectarea datelor
Colectarea datelor este primul pas în aplicarea analizei sentimentelor. Pentru a crea un multilingv model de analiză a sentimentelor, este important să obțineți date într-o varietate de limbi. Totul va depinde de calitatea datelor adunate, adnotate și etichetate. Puteți extrage date din API-uri, depozite open-source și editori.
Pasul 2: Preprocesare
Datele web colectate trebuie curățate și informațiile culese din acestea. Părțile textului care nu transmit niciun sens anume, cum ar fi „cel” „este” și altele, ar trebui eliminate. Mai mult, textul ar trebui grupat în grupuri de cuvinte pentru a fi clasificat pentru a transmite un sens pozitiv sau negativ.
Pentru a îmbunătăți calitatea clasificării, conținutul trebuie curățat de zgomot, cum ar fi etichete HTML, reclame și scripturi. Limba, lexicul și gramatica folosite de oameni sunt diferite în funcție de rețeaua socială. Este important să normalizați un astfel de conținut și să îl pregătiți pentru preprocesare.
Un alt pas critic în pre-procesare este utilizarea procesării limbajului natural pentru a împărți propoziții, a elimina cuvintele stop, a eticheta părți de vorbire, a transforma cuvintele în forma lor rădăcină și a transforma cuvintele în simboluri și text.
Pasul 3: Selectarea modelului
Model bazat pe reguli: Cea mai simplă metodă de analiză semantică multilingvă este bazată pe reguli. Algoritmul bazat pe reguli realizează analiza pe baza unui set de reguli predeterminate programate de experți.
Regula ar putea specifica cuvinte sau expresii care sunt pozitive sau negative. Dacă luați o recenzie a unui produs sau serviciu, de exemplu, aceasta ar putea conține cuvinte pozitive sau negative, cum ar fi „grozabil”, „lent”, „așteptați” și „util”. Această metodă facilitează clasificarea cuvintelor, dar ar putea clasifica greșit cuvintele complicate sau mai puțin frecvente.
Model automat: Modelul automat realizează o analiză multilingvă a sentimentelor fără implicarea moderatorilor umani. Deși modelul de învățare automată este construit folosind efortul uman, poate funcționa automat pentru a oferi rezultate precise odată dezvoltat.
Datele de testare sunt analizate și fiecare comentariu este etichetat manual ca pozitiv sau negativ. Modelul ML va învăța apoi din datele testului comparând noul text cu comentariile existente și clasificându-le.
Pasul 4: Analiză și evaluare
Modelele bazate pe reguli și modelele de învățare automată pot fi îmbunătățite și îmbunătățite în timp și experiență. Un lexicon de cuvinte utilizate mai rar sau scoruri live pentru sentimente multilingve poate fi actualizat pentru o clasificare mai rapidă și mai precisă.
Provocarea traducerii
Nu este suficientă traducerea? De fapt nu!
Traducerea implică transferul de text sau grupuri de texte dintr-o limbă și găsirea unui echivalent în alta. Cu toate acestea, traducerea nu este nici simplă, nici eficientă.
Asta pentru că oamenii folosesc limbajul nu numai pentru a-și comunica nevoile, ci și pentru a-și exprima emoțiile. În plus, există diferențe puternice între diferitele limbi, cum ar fi engleza, hindi, mandarina și thailandeza. Adăugați la acest amestec literar utilizarea emoțiilor, argoului, idiomurilor, sarcasmului și emoji-urilor. Nu este posibil să obțineți o traducere exactă a textului.
Unele dintre principalele provocări ale traducere automată sunt
- Subiectivitate
- Context
- Argo și idiomuri
- Sarcasm
- Comparații
- Neutralitate
- Emoji și utilizarea modernă a cuvintelor.
Fără a înțelege cu exactitate sensul intenționat al recenziilor, comentariilor și comunicării cu privire la produsele, prețurile, serviciile, caracteristicile și calitatea acestora, companiile nu vor putea înțelege nevoile și opiniile clienților.
Analiza sentimentelor multilingve este un proces provocator. Fiecare limbă are lexicul, sintaxa, morfologia și fonologia sa unice. Adaugă la asta cultura, argoul, sentimente exprimate, sarcasm și tonalitate, iar tu ai un puzzle provocator care are nevoie de o soluție eficientă de ML alimentată de AI.
Este necesar un set de date cuprinzător în mai multe limbi pentru a dezvolta un multilingv robust instrumente de analiză a sentimentelor care poate procesa recenzii și poate oferi informații puternice companiilor. Shaip este lider de piață în furnizarea de seturi de date personalizate, etichetate și adnotate în mai multe limbi, care ajută la dezvoltarea eficientă și precisă. soluții multilingve de analiză a sentimentelor.