Datele sunt superputerea care transformă peisajul digital în lumea de astăzi. De la e-mailuri la postări pe rețelele sociale, există date peste tot. Este adevărat că afacerile nu au avut niciodată acces la atât de multe date, dar este suficient să ai acces la date? Sursa bogată de informații devine inutilă sau depășită atunci când nu este procesată.
Textul nestructurat poate fi o sursă bogată de informații, dar nu va fi util întreprinderilor decât dacă datele sunt organizate, clasificate și analizate. Datele nestructurate, cum ar fi text, audio, videoclipuri și rețele sociale, se ridică la 80 -90% a tuturor datelor. În plus, abia 18% dintre organizații profită de datele nestructurate ale organizației lor.
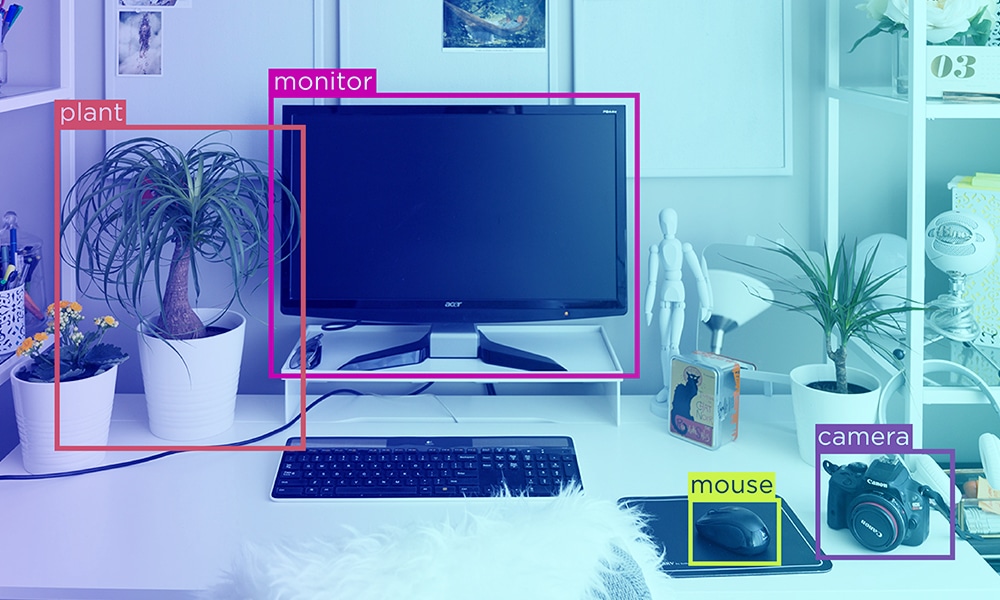
Cernerea manuală a teraocteților de date stocați pe servere este o sarcină care necesită timp și, sincer, este imposibilă. Cu toate acestea, odată cu progresele în învățarea automată, procesarea limbajului natural și automatizarea, este posibil să structurați și să analizați datele text rapid și eficient. Primul pas în analiza datelor este clasificarea textului.
Ce este clasificarea textului?
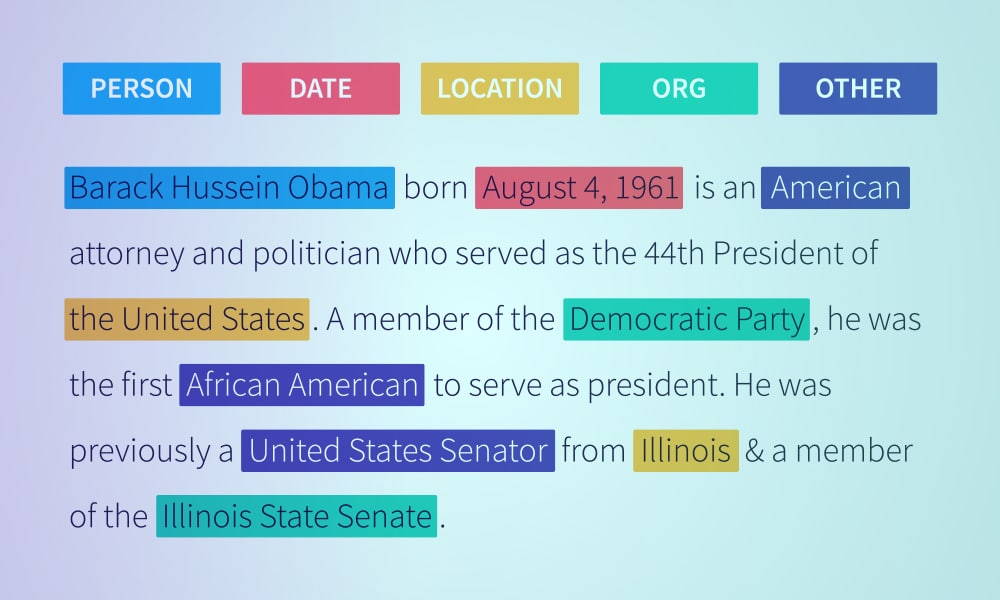
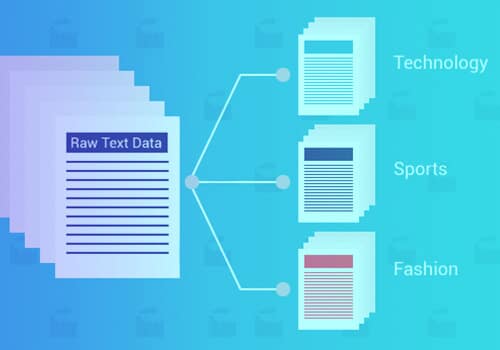
Clasificarea sau categorizarea textului este procesul de grupare a textului în categorii sau clase predeterminate. Folosind această abordare de învățare automată, orice text – documente, fișiere web, studii, documente juridice, rapoarte medicale și multe altele – poate fi clasificat, organizat și structurat.
Clasificarea textului este pasul de bază în procesarea limbajului natural care are mai multe utilizări în detectarea spam-ului. Analiza sentimentelor, detectarea intenției, etichetarea datelor și multe altele.
Cazuri de utilizare posibile ale clasificării textului
 Există mai multe beneficii ale utilizării clasificării textului de învățare automată, cum ar fi scalabilitatea, viteza de analiză, consistența și capacitatea de a lua decizii rapide pe baza conversațiilor în timp real.
Există mai multe beneficii ale utilizării clasificării textului de învățare automată, cum ar fi scalabilitatea, viteza de analiză, consistența și capacitatea de a lua decizii rapide pe baza conversațiilor în timp real.
Când modelul ML este antrenat pe AI care clasifică automat articolele în categorii prestabilite, puteți converti rapid browserele ocazionale în clienți.
Procesul de clasificare a textului
Procesul de clasificare a textului începe cu preprocesarea, selectarea caracteristicilor, extragerea și clasificarea datelor.

Preprocesare
Tokenizare: Textul este împărțit în forme de text mai mici și mai simple pentru o clasificare ușoară.
Normalizare: Tot textul dintr-un document trebuie să fie la același nivel de înțelegere. Unele forme de normalizare includ,
- Menținerea standardelor gramaticale sau structurale pe tot textul, cum ar fi eliminarea spațiilor albe sau a semnelor de punctuație. Sau menținerea minusculelor în tot textul.
- Eliminarea prefixelor și sufixelor din cuvinte și readucerea lor la cuvântul lor rădăcină.
- Eliminarea cuvintelor oprite precum „și” „este” „the” și altele care nu adaugă valoare textului.
Selectarea caracteristicilor
Selectarea caracteristicilor este un pas fundamental în clasificarea textului. Procesul are ca scop reprezentarea textelor cu cea mai relevantă caracteristică. Selectările de caracteristici ajută la eliminarea datelor irelevante și la îmbunătățirea acurateței.
Selectarea caracteristicilor reduce variabila de intrare în model utilizând numai cele mai relevante date și eliminând zgomotul. În funcție de tipul de soluție pe care îl căutați, modelele dvs. AI pot fi proiectate pentru a alege doar caracteristicile relevante din text.
Extracția elementelor
Extragerea caracteristicilor este un pas opțional pe care unele companii îl fac pentru a extrage caracteristici cheie suplimentare din date. Extragerea caracteristicilor folosește mai multe tehnici, cum ar fi maparea, filtrarea și gruparea. Avantajul principal al utilizării extragerii caracteristicilor este – ajută la eliminarea datelor redundante și la îmbunătățirea vitezei cu care este dezvoltat modelul ML.
Etichetarea datelor la categorii predeterminate
Etichetarea textului în categorii predefinite este pasul final în clasificarea textului. Se poate face în trei moduri diferite,
- Etichetare manuală
- Potrivire bazată pe reguli
- Algoritmi de învățare – Algoritmii de învățare pot fi clasificați în două categorii, cum ar fi etichetarea supravegheată și etichetarea nesupravegheată.
- Învățare supravegheată: modelul ML poate alinia automat etichetele cu datele clasificate existente în etichetarea supravegheată. Când datele clasificate sunt deja disponibile, algoritmii ML pot mapa funcția dintre etichete și text.
- Învățare nesupravegheată: se întâmplă atunci când există o lipsă de date etichetate existente anterior. Modelele ML folosesc algoritmi de grupare și bazați pe reguli pentru a grupa texte similare, cum ar fi bazate pe istoricul achizițiilor de produse, recenzii, detalii personale și bilete. Aceste grupuri largi pot fi analizate în continuare pentru a obține informații valoroase specifice clienților care pot fi utilizate pentru a concepe abordări personalizate ale clienților.
Există mai multe cazuri de utilizare pentru clasificarea textului în diferite industrii. Deși strângerea, gruparea, clasificarea și extragerea de informații valoroase din datele text a fost întotdeauna folosită în mai multe domenii, clasificarea textului își găsește potențialul în marketing, dezvoltare de produse, servicii pentru clienți, management și administrare. Ajută companiile să obțină informații competitive, cunoștințe despre piață și clienți și să ia decizii de afaceri bazate pe date.
Dezvoltarea unui instrument eficient și perspicace de clasificare a textului nu este ușoară. Cu toate acestea, având Shaip ca partener de date, puteți dezvolta un instrument de clasificare a textului bazat pe inteligență artificială eficient, scalabil și rentabil. Avem tone de seturi de date adnotate cu precizie și gata de utilizare care pot fi personalizate pentru cerințele unice ale modelului dvs. Transformăm textul tău într-un avantaj competitiv; luați legătura azi.